Chapter 4 Web Scraping: Data Extraction from Websites
4.1 The Toolbox
4.1.1 R as a Tool for Web Scraping
The basic R installation provides several high-level functions to download data from the Web. Most notably, when we download and install an R package with install.packages(), the package is downloaded from an R repository server somewhere on the Web. All of the basic web mining techniques introduced in this chapter can be implemented with two high-level R packages:
httr(Wickham 2022a) covers most of the functions we need in order to handle URLs and HTTP requests and responses.rvest(Wickham 2022b) provides high-level functions to parse and manipulate HTML.
As these packages are not distributed with the basic R installation, we have to install them first.
install.packages(c("httr", "rvest"))With these two packages we have all the basic ingredients we need to write simple web scrapers in R. More specialized packages needed for more advanced web mining tasks will be introduced step-by-step in the following chapters. In addition to R packages, we make use of so-called ‘developer tools’ provided in web browsers that help us to inspect the code of a website, test a website’s functionality, as well as monitor the web traffic between our computer and a given web server.
4.1.2 Web Browser and Developer Tools
Apart from R (and the respective R extensions), web browsers complement our web mining toolbox. Modern web browsers such as Google Chrome and Mozilla Firefox provide a set of tools that help web developers with the implementation of webpages and web applications. These tools are also very helpful for the development of web mining applications. In particular, they help us understand how a webpage is structured (by inspecting the HTML source code), what web technologies have been used to implement the website (particularly helpful for the scraping of dynamic webpages), and how a web client interacts with the server (by monitoring the HTTP traffic). Typically, we use the basic web browser functionality in combination with these developer tools in order to understand a website we want to extract data from better, before actually implementing a web scraper to extract the data. This section provides a brief overview over the most central developer tools for this task, focusing on Mozilla Firefox (the tools provided in Chrome are very similar to the ones discussed here).
Open Firefox and visit www.amazon.com. Suppose we are interested in writing a small program that automatically collects data on amazon product reviews. In order to do so we first have to figure out on which pages of this large website we find the reviews of specific products. We start with searching one specific product, a well-known book: Karl Marx’ ‘Capital’. When entering the search term karl marx capital into the amazon.com search function and hit the search symbol, the website returns a list of search results. One of them is likely ‘Capital: A Critique of Political Economy, Vol. 1’. Click on this search result, and the book’s product page will open.
As amazon.com is a dynamic website, URLs to its pages contain often a bunch of parameters that are not really needed for the URL to fulfill its function of pointing to the one specific document we are interested in. From playing around with the URL of this book’s page, we figure out that the URL can be shortened to https://www.amazon.com/dp/1453716548 and still provides the same page. From inspecting the links in the search result page, we can further figure out that 1453716548 is the product id of ‘Capital: A Critique of Political Economy, Vol. 1’.

Figure 4.1: Screen shot of amazon.com product webpage with the aggregate ranking of the product.
Further, by moving our mouse over the five-star rating symbol, a pop-up window is displayed giving some details about the overall rating statistics regarding this product. In this pop-up window, we see a link to see all reviews. Click on this link and inspect the page opened as well as the URL displayed in the browser bar. This is exactly the kind of page we want to extract data from. It displays all the reviews related to the product we are interested in. From inspecting the URL, we recognize that, again, it can be shortened (and still serves the same function): https://www.amazon.com/product-reviews/1453716548.
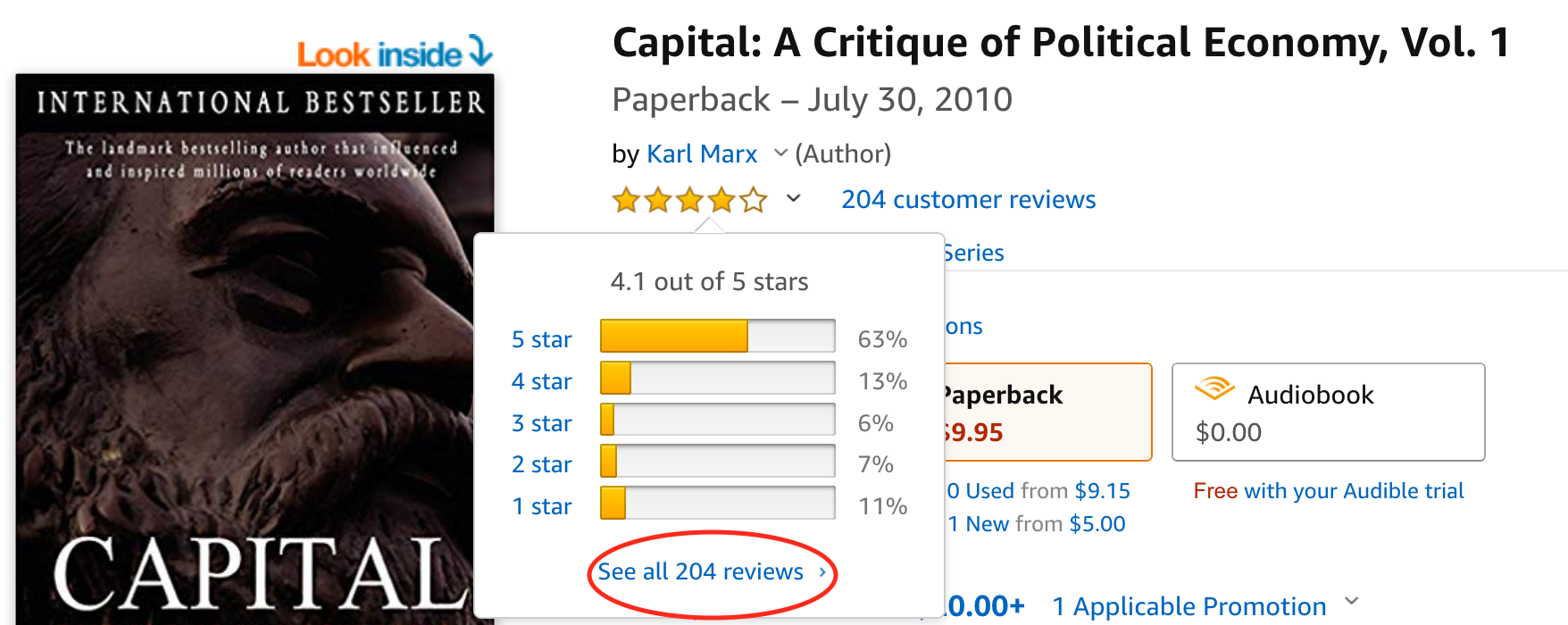
Figure 4.2: Screen shot of amazon.com product webpage and review summary pop-up window.
Simply from inspecting the website with our web browser we have figured out the first key ingredient to write our scraper later on. We know how the URLs pointing to product reviews are built: the base URL is https://www.amazon.com/product-reviews/, and adding a product id at the gives us the URL pointing to the reviews of the corresponding product.
Now we can start inspecting the structure of the product review page with the help of Firefox Developer Tools. For this, select in the Firefox menu bar Tools/Developer Tools/Inspector. A panel will open, displaying the HTML source code of this webpage. When moving the cursor over the webpage’s content, the Inspector tool will highlight the various respective components/elements of the page. When clicking on one of the highlighted elements, the element’s corresponding HTML code is shows in the code window (and vice versa when moving the cursor over the source code window).
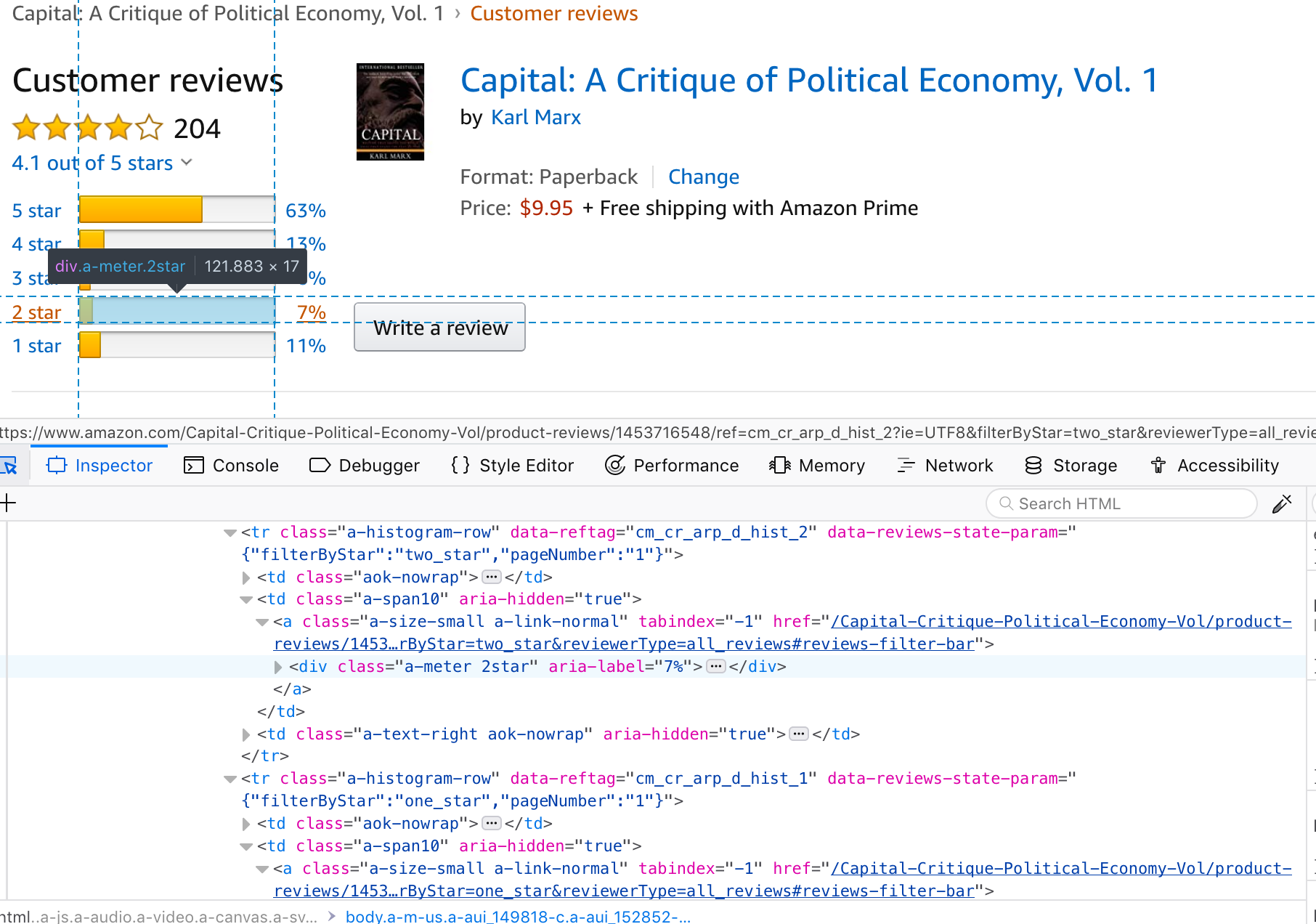
Figure 4.3: Screen shot of amazon.com product review page inspected with Firefox Developer Tools.
4.2 Components of a Scraper
Recall the three main tasks involved in many web data mining tasks seen in the first chapter:
- Communicating with the (physical) data source (the web server). That is, programatically requesting information from a particular website and handling the returned raw web data.
- Locating and extracting the data of interest from the document that constitutes the website.
- Serializing/reformatting the extracted data for further processing (analysis, visualization, storage).
We will build our first scraper consisting of three components along the lines of these three tasks. That is, based on the acquired knowledge about URLs, HTTP, and HTML, as well as the two R packages rvest and httr, we design a basic blueprint that we can later adapt to specific scraping tasks related to specific websites.
The aim of our scraper is to extract customer reviews from Amazon.8 In the version presented here, the scraper is very basic but already consists of the three main components that can be further elaborated in order to extend the scraper’s functionality in the future. We’ll go step by step through these components.
But first, let’s open a new R script in RStudio (File –> New File –> R Script), save the new script in the local working directory (with a meaningful name (such as amazon_ratings_scraper.R)) and enter some meta-data (as comments) in the top part of the script that will serve as documentation (what is the script for?, who wrote it?, etc.). Even if you are not working in a team on a programming task, always keep your code well documented (your future self will be grateful). In addition to the meta documentation, it is helpful to keep the first part of the script (here, ) reserved for code related to loading packages or additional functions, loading data, setting options, defining fix variables, and anything else on which the specific implementation further down will rely on.
# Web Scraper Blueprint
#
# This is a basic web scraper to automatically extract
# data about ratings and raters on amazon.com.
# See https://www.amazon.com/product-reviews/1453716548
# for an example of the type of page to be scraped.
#
# SETUP ------------------
# load packages
library(httr)
library(rvest)
# initiate fix variables
BASE_URL <- "https://www.amazon.com/product-reviews/"
PRODUCT_ID <- 1453716548In this case, we load the two R packages needed for the task and define two fix variables (which values won’t change during the execution of the script): BASE_URL, the first building block of the URLs pointing to the pages we potentially want to scrape, and PRODUCT_ID, the unique identifier of a product sold on amazon.com (for books, this is usually the PRODUCT_ID). Together, BASE_URL and the respective product id form the URL pointing to the webpage containing the reviews of the product (such as https://www.amazon.com/product-reviews/1453716548). Thus if we later want to use our script to scrape the reviews of another product, all we need to do is to define the right value for PRODUCT_ID and then run the whole script.
Now we implement the first component of the scraper, handling the URL, the HTTP request and the parsing of the response:
# I) URL, HANDLE HTTP REQUEST AND RESPONSE ----
# build URL for specific request
URL <- paste0(BASE_URL, PRODUCT_ID)
# fetch the website via a HTTP GET request
resp <- GET(URL)
# parse the content of the response (the html code)
resp_body <- read_html(resp) # or, alternatively: resp_body <- content(resp)At this stage, we have the entire webpage read into R (represented as an R object). We thus move on to the second component, in which we apply our knowledge about the structure of HTML and XPath in order to extract (‘scrape’) the data of interest (the stars rating, the name of the rater, the link to the profile of the rater, and the date of the rating) out of the page. By inspecting the raw HTML, we recognize that all the key parts of the document we are interested in, are embedded in HTML tags that have an attribute called data-hook with very intuitive values such as review-star-rating. The XPath we need to extract the HTML node with the dates of the ratings is thus rather short and simple: .//*[@data-hook='review-date']. In plain English this means ‘give me all the HTML tags that contain an attribute called data-hook with a value equal to 'review-date'’. In the other cases, we follow the same principle, and slightly extend the respective XPath to get what we want. The procedure we apply in this scraper to extract the data of interest is for each ‘variable’ (name, rating, etc.) exactly the same: 1. locate and extract the HTML node containing the data with XPath by means of the function html_nodes and 2., extract the data from that node. In some cases the data is text between tags (here we make use of the function html_text), in other cases it is an attribute value within a tag (here we make use of the function html_attr).
# II)
# extract the data of interest
# a) dates of ratings
ratings_dates_nodes <- html_nodes(resp_body, xpath=".//*[@data-hook='review-date']")
ratings_dates <- html_text(ratings_dates_nodes)
# b) ratings
rating_nodes <- html_nodes(resp_body, xpath=".//*[@data-hook='review-star-rating']/span")
ratings <- html_text(rating_nodes)
# c) raters
# names. this time, we directly access the text between tags via xpath's "text()"
raters_names_nodes <- html_nodes(resp_body, xpath=".//*[@class='a-profile-name']")[-1:-2]
raters_names <- html_text(raters_names_nodes)
# d) links to raters' profiles (this can also serve as unique rater-ids)
raters_link_nodes <- html_nodes(resp_body, xpath=".//a[@class='a-profile']")[-1:-2]
raters_links <- html_attr(raters_link_nodes, name = "href")Finally, we rearrange (and if necessary reformat) the extracted data for the purpose of further processing. In this simple scraper all we want as an output is to have the extracted data nicely arranged as a table in CSV format. In order to do so, we first put all the extracted data together in a data.frame (an R object class to work with data),
# Arrange the extracted data in a data frame
rating_tab <- data.frame(rating = ratings,
name = raters_names,
rater = raters_links,
date = ratings_dates)and then save the results in a CSV-file on disk via the function write.csv.
# III)
# write extracted data to csv
write.csv(rating_tab,
file="data/amazon_ratings.csv",
row.names = FALSE)Now we can inspect the results either directly in RStudio (View(rating_tab)) or by opening the saved file with another program such as Excel or we can integrate it in a dynamic document such as the files underlying this book. The following table shows the data stored in rating_tab9.
| rating | date |
|---|---|
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on December 11, 2022 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on October 1, 2017 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on September 12, 2018 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on December 29, 2008 |
| 4.0 out of 5 stars | Reviewed in the United States 🇺🇸 on April 4, 2011 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on August 10, 2012 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on February 7, 2021 |
| 4.0 out of 5 stars | Reviewed in the United States 🇺🇸 on November 2, 2019 |
| 5.0 out of 5 stars | Reviewed in the United States 🇺🇸 on August 19, 2022 |
| 4.0 out of 5 stars | Reviewed in the United States 🇺🇸 on January 8, 2022 |
The modular composition of this basic web scraper allows us to productively think about potential refinements. Regarding the first component, we might be concerned about robustness. What would currently happen, if no review exists for the entered PRODUCT_ID or if the entered id does not exist at all? With respect to the second component, we might want to extend the data extracted and also extract the actual text of the reviews. Finally, regarding the last component, we might want to consider re-using the extracted links to the raters’ profiles in another scraping exercise and/or directly feed the extracted data into an SQL-database (instead of saving it in a CSV-file). Note how all these potential extensions of one of the components are essentially not affecting the other components. This helps us to break down the development of a more sophisticated web scraper into smaller problems that can be addressed piece by piece.
Further, we can test the scraper by scraping a variety of product reviews. All we need to do is to change the PRODUCT_ID variable. We thus can use the simple scraper implemented above in order to extract data on reviews of various products on amazon.com. A most straightforward was to do this is to use a loop, as introduced in the following section and then applied to extend our basic amazon review scraper.
4.3 Writing scrapers
In the previous week we looked at the very basics of using R: how to initiate a variable, R as a calculator, data structures, functions, etc. All of this was rather focused on executing command after command or a number of commands at once in an ‘interactive’ R session. Apart from the definition of a function, we haven’t really looked at ‘how to program’ with R. A large part of basic programming has to do with automating the execution of a number of commands conditional on some control statements. That is, we want to tell the computer to ‘do’ something until a certain goal is reached. In the simplest case this boils down to a control flow statement that specifies an iteration, a so-called ‘loop’.
4.3.1 Loops
A loop is typically a sequence of statements that is executed a specific number of times. How often the code ‘inside’ the loop is executed depends on a (hopefully) clearly defined control statement. If we know in advance how often the code inside of the loop has to be executed, we typically write a so-called ‘for-loop’. If the number of iterations is not clearly known before executing the code, we typically write a so-called ‘while-loop’. The following subsections illustrate both of these concepts in R.
4.3.1.1 For-loops
In simple terms, a for-loop tells the computer to execute a sequence of commands ‘for each case in a set of n cases’. For example, a for-loop could be used to sum up each of the elements in a numeric vector of fix length (thus the number of iterations is clearly defined). In plain English, the for-loop would state something like:“Start with 0 as the current total value, for each of the elements in the vector add the value of this element to the current total value.” Note how this logically implies that the loop will ‘stop’ once the value of the last element in the vector is added to the total. Let’s illustrate this in R. Take the numeric vector c(1,2,3,4,5). A for loop to sum up all elements can be implemented as follows:
# vector to be summed up
numbers <- c(1,2,3,4,5)
# initiate total
total_sum <- 0
# number of iterations
n <- length(numbers)
# start loop
for (i in 1:n) {
total_sum <- total_sum + numbers[i]
}
# check result
total_sum## [1] 15# compare with result of sum() function
sum(numbers)## [1] 15In some situations a simple for-loop might not be sufficient. Within one sequence of commands there might be another sequence of commands that also has to be executed for a number of times each time the first sequence of commands is executed. In such a case we speak of a ‘nested for-loop’. We can illustrate this easily by extending the example of the numeric vector above to a matrix for which we want to sum up the values in each column. Building on the loop implemented above, we would say ‘for each column j of a given numeric matrix, execute the for-loop defined above’.
# matrix to be summed up
numbers_matrix <- matrix(1:20, ncol = 4)
numbers_matrix## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20# number of iterations for outer loop
m <- ncol(numbers_matrix)
# number of iterations for inner loop
n <- nrow(numbers_matrix)
# start outer loop (loop over columns of matrix)
for (j in 1:m) {
# start inner loop
# initiate total
total_sum <- 0
for (i in 1:n) {
total_sum <- total_sum + numbers_matrix[i, j]
}
print(total_sum)
}## [1] 15
## [1] 40
## [1] 65
## [1] 904.3.1.2 While-loop
In a situation where a program has to repeatedly run a sequence of commands but we don’t know in advance how many iterations we need in order to reach the intended goal, a while-loop can help. In simple terms, a while loop keeps executing a sequence of commands as long as a certain logical statement is true. The flow chart in Figure 4.4 illustrates this point.
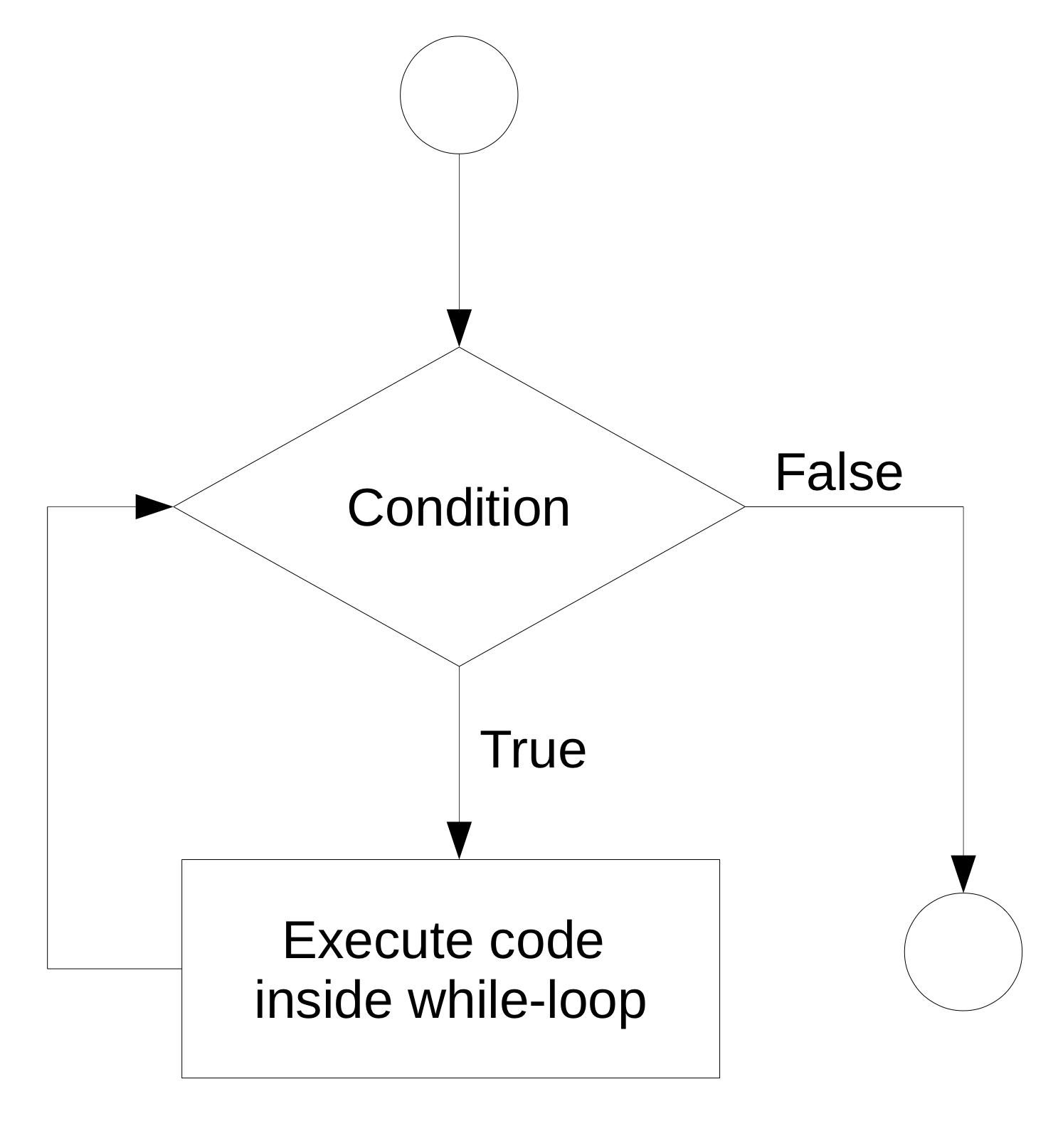
Figure 4.4: While-loop illustration.
For example, a while-loop in plain English could state something like “start with 0 as the total, add 1.12 to the total until the total is larger than 20.” We can implement this in R as follows.
# initiate starting value
total <- 0
# start loop
while (total <= 20) {
total <- total + 1.12
}
# check the result
total## [1] 20.164.3.2 Loops and Web Scraping
The two types of loops are very helpful in many web scraping tasks. Note how the web scraping example of the previous chapter (‘blueprint’) is only designed to run for one specific Amazon product review (based on the product id). We can easily imagine to extend the scraper to gather more data. For example, we could first collect a bunch of product ids for which we want to collect all reviews. Thus, we could implement this with a for-loop that iterates through each of the product ids and stops once all of the product ids have been used. Alternatively, we could imagine an extension of the basic review scraper that would first scrape all the reviews of one product id and then continue to scrape all reviews of all the products that the reviewer of the initial review also reviewed, and so on until we have collected a certain number of reviews (or collected reviews of a certain number of reviewers, etc.). The following extended examples show the practical use of loops in different web scraping contexts.
4.4 Scraping Tutorial I: A Simple Text Scraper for Wikipedia
In this exercise we write an R script that looks up a bunch of terms in Wikipedia, parses the search results, extracts the text of the found page, and saves it locally as a text file.
As usual, we first inspect the website’s source code (with the help of developer tools) and have a close look at the part of the website containing the search field. We recognize that the HTML form’s action attribute is indicating a relative link /w/index.php. This tells us that once a user hits enter to submit what she entered in the form, the search term will be further processed by a PHP script on Wikipedia’s server. From this, however, we do not know yet, how the data will be submitted, or in other words, how we do have to formulate either a GET or POST request in order to mimic a user typing requests into the search field.
In order to understand how the search function on Wikipedia pages works under the hood, we open the ‘Network’ panel in the Firefox Developer Tools, and switch the ‘HTML’ filter on (as we are only interested in the traffic related to HTML documents). We then type ‘Donald Trump’ in the search field of the Wikipedia page and hit enter. The first entry of the network panel shows us the first transfer recorded after we hit enter. It tells us that the search function works as such that a GET request with an URL pointing to the PHP-script discovered above is sent to the server.

Figure 4.5: Firefox Development Tools: Network Panel.
We can copy the exact URL of the GET request by left-clicking on it in the network panel and select Copy/Copy URL and then verify that this is actually how the Wikipedia search function works by pasting the copied URL10 back into the Firefox address bar and hit enter. We can then test whether we correctly understand how the URL for a query needs to be constructed by replacing the Donald+Trump part with Barack+Obama and see what we get. Based on our insights about how the search field on Wikipedia works, we can start to implement our scraper.
In the documentation of this script it is helpful to point out that there are two important types of URLs to be considered here: one as an example of a page to scrape data from, and one pointing to the search function. Since different parts of the URL to Wikipedia’s search function will become handy, we define the parsed URL from our ‘Donald Trump’ example as a fix variable. The aim of the scraper is to extract the text of the returned search result (the found Wikipedia entry) and store it locally in a text file. Therefore, we already define an output directory (RESULTS_DIR <- "data/wikipedia") where results should be stored.
# Wikipedia Search Form Scraper
#
# This is a basic web scraper to automatically look up
# search terms in Wikipedia and extract the text of the
# returned page.
# See https://en.wikipedia.org/wiki/Donald_Trump
# for an example of the type of page to be scraped.
# SETUP ------------------
# load packages
library(httr)
library(xml2)
library(rvest)
library(stringi)
# initiate fix variables
SEARCH_URL <- parse_url("https://en.wikipedia.org/w/index.php?+
search=Donald+Trump&+
title=Special%3ASearch&go=Go")
SEARCH_TERM <- "Barak Obama"
RESULTS_DIR <- "data/wikipedia/"As we have parsed the rather complex URL to perform searches on Wikipedia from the example above, we can simply modify the resulting object by replacing the respective parameter (search): SEARCH_URL$query$search <- SEARCH_TERM and then use the function build_url() to construct the URL for an individual request. The rest of the first component is straightforward from the blueprint.
# I) URL, HANDLE HTTP REQUEST AND THE RESPONSE ----
# Build the URL (update search term)
SEARCH_URL$query$search <- SEARCH_TERM
# fetch the website via a HTTP GET request
URL <- build_url(SEARCH_URL)
search_result <- GET(URL)
# parse the content of the response (the html code)
search_result_html <- read_html(search_result) In the second component, we first identify the part of the parsed HTML document that we want to extract. In the case of how Wikipedia pages are currently built, it turns out that a straightforward way to do this is to select all paragraphs (<p>) that are embedded in a <div>-tag of class mw-parser-output. The xpath expression ".//*[@class='mw-parser-output']/p" captures thus all the HTML elements with content of interest. In order to extract the text from those elements we simply apply the html_text()-function.
# II) filter HTML, extract data ----
xp <- ".//*[@class='mw-parser-output']/p"
content_nodes <- html_nodes(search_result_html,
xpath = xp)
content_text <- html_text(content_nodes)Finally, in the last component we define the name of the text-file to which we want to save the extracted text.11
# III) write text to file ----
filepath <- paste0(RESULTS_DIR,
stri_replace_all_fixed(str = SEARCH_TERM,
" ", ""),
".txt" )
write(content_text, filepath)Putting all parts together, we can start using this script to automate the extraction of text from Wikipedia for any search term. Given the previous exercise, it should be straightforward to tweak this script in order to extract text from various pages based on a number of search terms (via a loop).
# Wikipedia Search Form Scraper
#
# This is a basic web scraper to automatically look up
# search terms in Wikipedia and extract the text of the
# returned page.
# See https://en.wikipedia.org/wiki/Donald_Trump
# for an example of the type of page to be scraped.
# SETUP ------------------
# load packages
library(httr)
library(xml2)
library(rvest)
library(stringi)
# initiate fix variables
SEARCH_URL <- parse_url("https://en.wikipedia.org/w/index.php?+
search=Donald+Trump&+
title=Special%3ASearch&go=Go")
SEARCH_TERM <- "Barak Obama"
RESULTS_DIR <- "data/wikipedia/"
# I) URL, HANDLE HTTP REQUEST AND THE RESPONSE ----
# Build the URL (update search term)
SEARCH_URL$query$search <- SEARCH_TERM
# fetch the website via a HTTP GET request
URL <- build_url(SEARCH_URL)
search_result <- GET(URL)
# parse the content of the response (the html code)
search_result_html <- read_html(search_result)
# II) filter HTML, extract data ----
xp <- ".//*[@class='mw-parser-output']/p"
content_nodes <- html_nodes(search_result_html,
xpath = xp)
content_text <- html_text(content_nodes)
# III) write text to file ----
filepath <- paste0(RESULTS_DIR,
stri_replace_all_fixed(str = SEARCH_TERM,
" ", ""),
".txt" )
write(content_text, filepath)4.5 Scraping Tutorial II: Extracting U.S. Senate Roll Call Data
A simple but very practical web scraping task is to extract data from HTML tables on a website. If we have to do this only once, R might not even be necessary but we might get the data simply by marking the table in a web browser and copy-pasting it into a spreadsheet program such as Excel (and saving it as CSV etc.). However, it is likely the case that we have to repeatedly extract various tables from the same website. The following exercise shows how this can be done in the context of data on roll-call voting in the U.S. Senate. The scraper is made to extract all roll call voting results for a given list of congresses, and combine them in one table. The data will be automatically extracted from the official website of the U.S. Senate www.senate.gov where all data for the last few congresses are available on pages per session and congress. For example, the URL www.senate.gov/legislative/LIS/roll_call_lists/vote_menu_113_1.htm is pointing to the page providing the data for the first session of the 113th U.S. Congress. First, we inspect the source code with developer tools and figure out how the URLs are constructed. Based on this, we define the header section of a new R script for this scraper. As we want to extract data on voting results from various congresses and sessions, we define the fixed variables CONGRESS and SESSION as vectors.
# Roll Call Data Scraper (HTML Tables)
#
# This is a basic web scraper to automatically extract
# data on roll call vote outcomes in the U.S. Senate.
# The data is extracted directly form
# the official government website www.senate.gov
# (www.senate.gov/legislative/LIS/roll_call_lists/vote_menu_113_1.htm)
# SETUP ------------------
# load packages
library(httr)
library(xml2)
library(rvest)
# initiate fix variables
BASE_URL <- "https://www.senate.gov/legislative/LIS/roll_call_lists/"
CONGRESS <- c(110:114)
SESSION <- c(1, 2)Following the blueprint outlined in the previous week, we write the three components of the scraper. However, in this case we we aim to place all the components in a for-loop in order to iterate through all the pages we want to extract the tables with voting results from. The three components of our web scraper will thus form the ‘body’ of the for-loop. That is, they build the sequence of commands that are executed sequentially until we have all the data we want to collect. From inspecting the website of the U.S. Senate (see www.senate.gov/legislative/LIS/roll_call_lists/vote_menu_113_1.htm), we learn that in order to collect all the roll-call data from the 110th to the 114th congress, we have to iterate not only through each congress but also through each of the two sessions in one congress (each congress consists of two sessions). Thus for each congress and each session per congress, we want to extract the voting data. This implies a nested for-loop: in the outer loop we iterate through individual congresses, in the inner loop (that is, given a specific congress), we iterate through the sessions.
Another key aspect to know before getting started is to understand what the result of each iteration is and how we collect/‘merge’ the individual results. As the overall goal of the scraper is to extract data from HTML tables, a reasonable format to store the data of each iteration is a data.frame. Thus, each iteration will result in a data.frame, which implies that we have to store each of these data-frames while running the loop. We can do this with a list. Before starting the loop, we initiate an empty list all_tables <- list(NULL). Then, within the loop, we add each of the extracted tables (now objects of class data.frame) as an additional element of that list. The following code chunk contains the blueprint for the loop following this strategy (without the actual loop body, i.e., the three scraper components).
# initiate variables for iteration
n_congr <- length(CONGRESS)
n_session <- length(SESSION)
all_tables <- list(NULL)
# start iteration
for (i in 1:n_congr) {
for (j in 1:n_session) {
# ADD COMPONENTS I TO III HERE!
# add resulting table to list
rc_table_list <- list(rc_table)
all_tables <- c(all_tables, rc_table_list)
}
}Note that in order to ‘add’ an extracted table (here: a data-frame called rc_table) to the list, we first have to ‘put’ it in a list rc_table_list <- list(rc_table) and then add it to the list containing all tables: all_tables <- c(all_tables, rc_table_list). The code above does not do anything yet on its own. We have to fill in the three components containing the actual scraping tasks in the body of the loop. When developing each of the components it is helpful to just write them for one iteration (ignoring the loop for a moment). This way we can test each component step by step before iterating over it many times. A simple way to do this is to just manually assign values to the index-variables i and j: i <- 1, j <- 1.
The first component (interaction with the server, parse response…) is then straightforwardly implemented and tested as
# I) Handle URL, HTTP request and response, parse HTML
# build the URL
page <- paste0("vote_menu_", CONGRESS[i], "_", SESSION[j], ".htm")
rc_url <- paste0(BASE_URL, page)
# request webpage, parse results
rc_resp <- GET(rc_url)
rc_html <- read_html(rc_resp)As usual, we have to figure out (with the help of developer tools) how to extract the specific part of the HTML-document which contains the data of interest. In this particular case the xpath expression ".//*[@id='secondary_col2']/table" provides the result we are looking for in the second component:
# II) Extract the data of interest
# extract the table
xp_tab <- ".//*[@id='secondary_col2']/table"
rc_table_node <- html_node(rc_html,
xpath = xp_tab)
rc_table <- html_table(rc_table_node)Finally in the last component, we prepare the extracted data for further processing. When looking at the result of the previous component (head(rc_table)), we note that the extracted table does not actually contain information about which congress and session it is from. We add this information by adding two new columns.
# III) Format and save data for further processing
# add additional variables
rc_table$congress <- CONGRESS[i]
rc_table$session <- SESSION[j]With this we have the extracted data from one iteration (one congress-session pair) in the form we want. Once we have tested each of the components and are happy with the overall result for one iteration, we can add them to the body of the loop and put all parts together.
# Roll Call Data Scraper (HTML Tables)
#
# This is a basic web scraper to automatically extract
# data on roll call vote outcomes in the U.S. Senate.
# The data is extracted directly form
# the official government website www.senate.gov
#(www.senate.gov/legislative/LIS/roll_call_lists/vote_menu_113_1.htm)
# SETUP ------------------
# load packages
library(httr)
library(xml2)
library(rvest)
# initiate fix variables
BASE_URL <- "https://www.senate.gov/legislative/LIS/roll_call_lists/"
CONGRESS <- c(110:114)
SESSION <- c(1, 2)
# SCRAPER ------------------
# initiate variables for iteration
n_congr <- length(CONGRESS)
n_session <- length(SESSION)
all_tables <- list(NULL)
# start iteration
for (i in 1:n_congr) {
for (j in 1:n_session) {
# I) Handle URL, HTTP request and response, parse HTML
# build the URL
page <- paste0("vote_menu_",
CONGRESS[i], "_", SESSION[j],
".htm")
rc_url <- paste0(BASE_URL, page)
# request webpage, parse results
rc_resp <- GET(rc_url)
rc_html <- read_html(rc_resp)
# II) Extract the data of interest
# extract the table
xp_tab <- ".//*[@id='secondary_col2']/table"
rc_table_node <- html_node(rc_html,
xpath = xp_tab )
# alternatively: html_node(rc_html, css = "table")
rc_table <- html_table(rc_table_node)
# III) Format and save data for further processing
# add additional variables
rc_table$congress <- CONGRESS[i]
rc_table$session <- SESSION[j]
# add resulting table to list
rc_table_list <- list(rc_table)
all_tables <- c(all_tables, rc_table_list)
}
}As a last step, once the loop has finished, we can stack the individual data-frames together to get one large data-frame which we then can store locally as a csv-file to further work with the collected data.
# combine all tables in one:
big_table <- do.call("rbind", all_tables)# write result to file
write.csv(x = big_table,
file = "data/senate_rc.csv",
row.names = FALSE)The first rows and columns of the resulting csv-file:
## # A tibble: 6 × 2
## `Vote (Tally)` Result
## <chr> <chr>
## 1 (00442) 442 (93-0) Confirmed
## 2 (00441) 441 (76-17) Agreed to
## 3 (00440) 440 (48-46) Rejected
## 4 (00439) 439 (70-25) Agreed to
## 5 (00438) 438 (50-45) Rejected
## 6 (00437) 437 (24-71) RejectedReferences
Recall from Edelman (2012), how the fact that shopping online is somehow way more transparent than offline is interesting from an economics point of view and can be exploited by means of web scraping.↩︎
The columns identifying the raters are excluded from the table.↩︎
https://en.wikipedia.org/w/index.php?search=Donald+Trump&title=Special%3ASearch&go=Go↩︎The function
stri_replace_all_fixed()is used here to automatically remove all the white space from the search term. Thus, in the case of a search with the term “Donald Trump”, the extracted data would be stored in a text-file with the pathdata/wikipedia/DonaldTrump.txt.↩︎