Chapter 2 The Internet as a Data Source
2.1 The Internet: Physical and Technological Layer
The Internet is fundamentally a network of small local physical computer networks (connected via copper cables, fiber optic cables, or radio waves). Figure 2.1 depicts a typical local network scheme found in a private home. By connecting a computer in your home to the Internet, your local network, which may include your laptop, phone, printer, modem, and router, becomes a part of this vast network of networks.
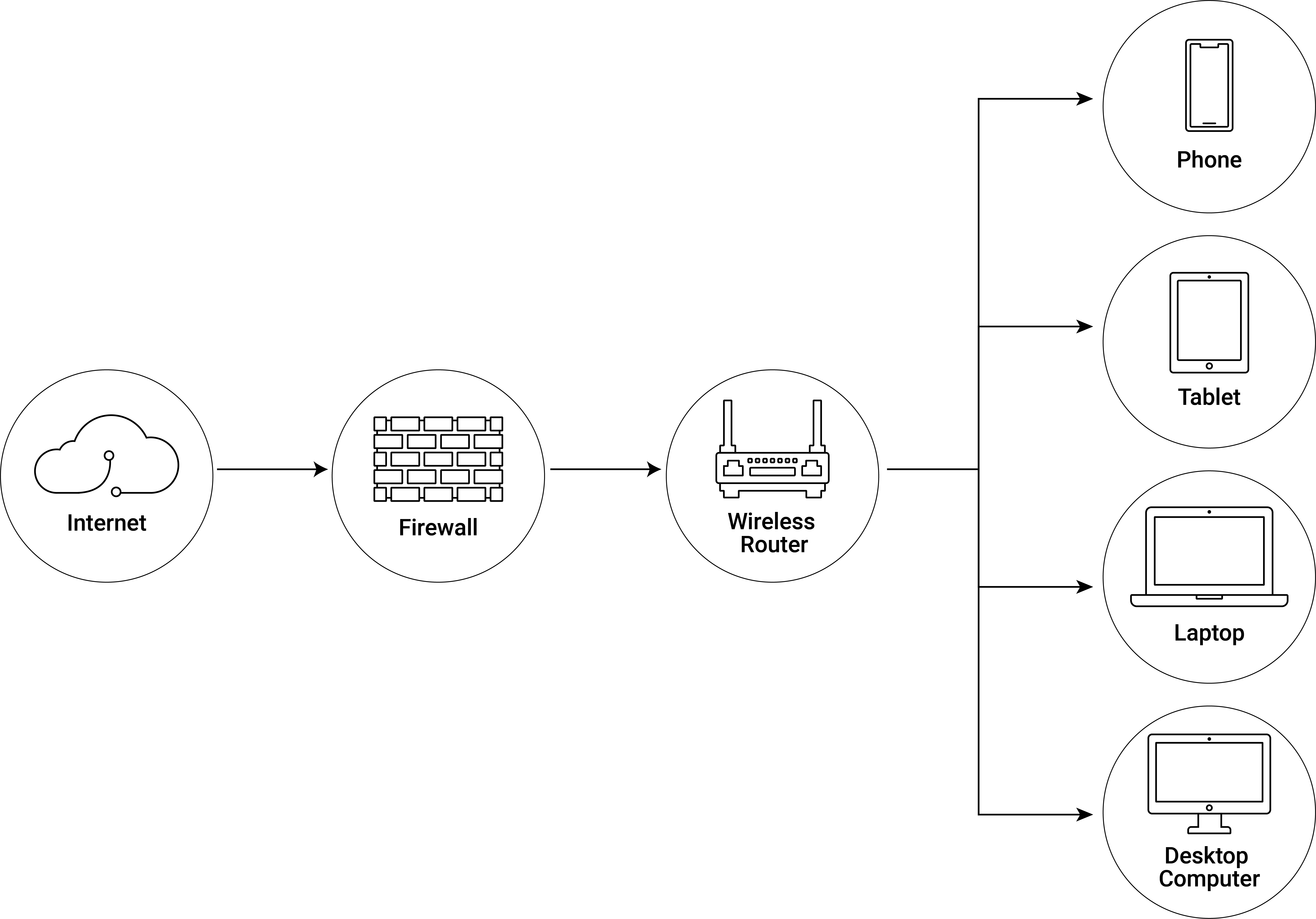
Figure 2.1: Illustration of a home network (WLAN).
Internet Service Providers (ISP) serve as hubs, connecting many of the smaller local networks. To get Internet access at home, one usually subscribes to an ISP, that connects the home network to the rest of the Internet via cable TV, phone line, or optical fiber. Larger network infrastructure is then used to connect different ISPs across country borders and even across oceans.
{Routers are the central nodes in most parts of the Internet, connecting different devices and managing the data traffic between them. In order for routers to work properly, each computer/device in the network (and the Internet overall) needs a standardized address, i.e., the IP (Internet Protocol) address that uniquely identifies it in the network. Usually the local router in our home assigns IP addresses that are valid within the local network, and the router itself has an IP address that identifies it in the outside world (in other parts of the Internet).1 IP addresses are so far based on four numbers (IPv4) with 8 bits each (values of 0 to 255 in decimal).2 A typical IP address looks something like this: 216.58.219.196. In order to request a document (i.e., a website) from a computer in the Internet we would thus have to know this computer’s IP address. Fortunately, the Domain Name System (DNS) does the the address ‘look up’ for us by translating URLs (e.g., www.google.com) to IP addresses.
We can demonstrate this in the (Mac OS) terminal by calling a program called nslookup (for ‘Name Server look up’) in order to look up the IP-address of the server with the domain www.google.com.3
nslookup www.google.com## Server: 127.0.0.53
## Address: 127.0.0.53#53
##
## Non-authoritative answer:
## Name: www.google.com
## Address: 142.250.203.100
## Name: www.google.com
## Address: 2a00:1450:400a:808::2004The first two lines refer to the local DNS server. The last line of the response gives us the IP address of one of Google’s servers. When typing an URL into the address bar of a web browser, the same is essentially happening ‘under the hood’.
As the Internet is a large network consisting of various small local networks, requesting data from a particular website means sending data packets from your local network via several routers to a machine in another physical local network (potentially far away). Again, we can make use of our computer to illustrate this point. By means of the application traceroute we record what nodes—usually routers with an IP address—the data packet passes through in order to reach the website/server behind the domain (in this example, the homepage of Princeton University).4
traceroute www.princeton.edu## traceroute to www.princeton.edu (104.18.4.101), 30 hops max, 60 byte packets
## 1 fritz.box (192.168.178.1) 7.073 ms 7.031 ms 7.023 ms
## 2 790oer1.fiber7.init7.net (212.51.143.1) 12.163 ms 12.154 ms 12.146 ms
## 3 r1.790see.fiber7.init7.net (141.195.82.131) 12.187 ms 13.350 ms 13.341 ms
## 4 r1glb2.core.init7.net (141.195.82.128) 13.308 ms 13.301 ms 13.294 ms
## 5 r2zrh2.core.init7.net (5.180.135.183) 14.167 ms 14.160 ms 14.152 ms
## 6 r1zrh3.core.init7.net (5.180.135.166) 14.154 ms 3.739 ms 4.904 ms
## 7 r1zrh5.core.init7.net (5.180.134.39) 4.871 ms 5.373 ms 5.326 ms
## 8 194.42.48.14 (194.42.48.14) 4.761 ms 5.851 ms 15.364 ms
## 9 104.18.4.101 (104.18.4.101) 8.931 ms 8.922 ms 8.915 msAs IP-addresses can be mapped to geographical locations (to a certain degree of precision), we can actually trace the data packet we are sending through the Internet on a map. See, e.g., https://stefansundin.github.io/traceroute-mapper/ for mapping of traceroute terminal output (example in Figure 2.2) or http://www.dnstools.ch/visual-traceroute.html for host traceroute.
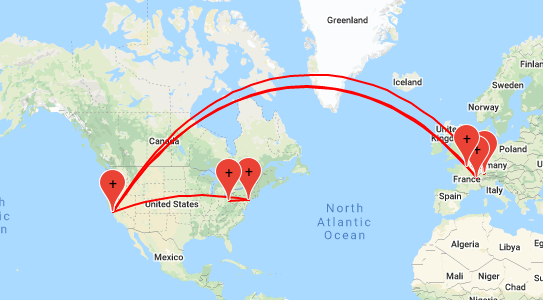
Figure 2.2: Map illustrating the route the data packets took to reach princeton.edu. Source: https://stefansundin.github.io/traceroute-mapper/.
Simply contacting a server in the Internet needs only very little data to be transmitted. Commonly, we transfer/download a lot of data when using the Internet, though. If the data to be transferred between two devices on the Internet is larger than one packet, the devices, following the Transmission Control Protocol (TCP), split the data into pieces and ensure that all pieces arrive at the destination. Thus the receiver recognizes due to TCP that a part is missing and will ask the sender to resend it. Each packet (piece) is thus labeled with a number and the receiver checks whether all the numbers have arrived in order to make sure the data is complete.
2.3 Economic data generating processes online
One of the main reasons making the Internet an interesting data source for economic research is that the availability of information on economic interactions (e.g., between buyer and seller, politician and voter, author and publisher, etc.) is a core part of the business model of commercial websites (or of the raison d’être of non-commercial websites). Thus the social/economic (not the technical or legal) aspects necessary to make a website work often demand a certain degree of transparency regarding the information involved in the social/economic interactions happening on that website. Edelman (2012, 190) illustrates this point in the context of consumer goods and online auctions: “Consumers and competitors push websites to post remarkable amounts of information online. For example, most retail booksellers would hesitate to share information about which items they sold. Yet eBay posts the full bid history for every item offered for sale, and Amazon updates its rankings of top-selling items every hour.”
The following list gives an overview of the various ways automated data extraction from the web has served as a basis for research projects in different sub-fields of economics (based on Edelman (2012)):
- Microeconomics. Bajari and Hortaçsu (2003) “The Winner’s Curse, Reserve Prices, and Endogenous Entry: Empirical Insights from eBay Auctions.”: Bid data from coin sales on eBay reveal bidder behavior in auctions, including the magnitude of the winner’s curse.
- Macroeconomics and Monetary Economics. Cavallo (2016). “Scraped Data and Sticky Prices.”: Daily price data from online supermarkets reveal price adjustment and price stickiness.
- Financial Economics. Antweiler and Frank (2004). “Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards.”: Finds that online discussions help predict market volatility; effects on stock returns are statistically significant but economically small.
- Health, Education, and Welfare. Ginsberg et al. (2009) “Detecting Influenza Epidemics Using Search Engine Query Data.”: Trends in users’ web searches identify influenza epidemics.
- Industrial Organization. Chevalier and Goolsbee (2003). “Measuring Prices and Price Competition Online: Amazon.com vs. BarnesandNoble.com.”: Uses publicly available price and rank data to estimate demand elasticities at two leading sellers of online books, finding greater price sensitivity at Barnes & Noble than at Amazon.
References
IP addresses are assigned following the Dynamic Host Configuration Protocol (DHCP).↩︎
Due to the insufficient amount of possible unique numbers in this system, it is about to be extended to IPv6 (eight numbers with 16 bits each).↩︎
The same command is also available on Windows machines with identical or very similar usage in the Windows (DOS) command line (depending on the Windows version). See https://www.computerhope.com/nslookup.htm for details.↩︎
Note that the code shown below runs on a Mac or Linux terminal. Use
tracert google.comon Windows (DOS).↩︎The researchers also provide a website with network diagrams and additional statistics based on their method for various countries.↩︎