Chapter 7 Advanced Web Scraping: Data Extraction from Dynamic Websites
7.1 What if there is no API?
The programmable web offers new opportunities for web developers to integrate and share data across different applications over the web. In recent chapters we have learned about some of the key technological aspects of this programmable web and dynamic websites:
- Web Application Programming Interfaces (web APIs): A predefined set of HTTP requests/responses for querying data hosted on the server (or providing data from the client side).
- Extensible Markup Language (XML) and JavaScript Object Notation (JSON): Standards/Syntax to format data that are intended to be both human- and machine-readable and that therefore facilitate the exchange of data between different systems/applications over the web.
- JavaScript/AJAX: A programming language and framework designed to build interactive/dynamic websites. In the AJAX framework a JavaScript program built into an HTML-document/website, could, for example, be triggered by the user clicking on a button. This program might then automatically request additional data (in XML-format) from the server via an API and embed this new data dynamically in the HTML-document on the client-side.
In the context of web mining, these new technologies mean that automated data collection from the web can get both substantially easier or substantially more difficult in comparison to automated data collection from the ‘old’ web. Whether one or the other is the case essentially depends on whether a dynamic website relies on an API, and if so, whether this API is publicly accessible (and hopefully free of charge). If the latter is the case, our web mining task is reduced to (a) understanding how the specific API works (which is usually very easy, since open APIs tend to come with detailed and user-friendly documentations) and (b) knowing how to extract the data of interest from the returned XML or JSON documents (which is usually substantially easier than scraping data from HTML pages). In addition, there might already be a so-called ‘API client’ or ‘wrapper’ implemented in an R package that does all this for us, such as the twitteR package to collect data from one of Twitter’s APIs. If such a package is available we only have to learn how it can be applied to systematically collect data from the API (as shown in the previous chapter).
In cases where no API is available, the task of automated data collection from a dynamic website/web application can get much more complex because not all the data is provided when we issue a simple GET request based on an URL pointing to a specific webpage. This manuscript covers some of the frequently encountered aspects and difficulties for web mining related to such dynamic sites. The important take-away message is, however, that—unlike with the ‘old’ web—there is not one simple generic approach on which we can build when writing a scraper. The techniques necessary to scrape dynamic websites are much more case-specific and might even require substantial knowledge of JavaScript and other web technologies. Providing all the techniques for automated data collection from dynamic websites would thus go far beyond the scope of this course. However, there is also an alternative approach to dealing with such websites which can be employed rather generally: instead of writing a program that ‘decomposes’ the website to scrape the data from it, we can rely on a framework that allows us to programmatically control an actual web browser and thus simulate a human using a browser (including scrolling, clicking, etc.). That is, we use so-called ‘web browser automation’ instead of simple scrapers.
7.2 Scraping dynamic websites
The first step of dealing with a dynamic website in a web mining task is to figure out where the data we see in the browser is actually coming from. This is where the ‘Developer Tools’ provided with modern browsers such as Chrome or Firefox come into play. The ‘Network Panel’ in combination with the source-code inspector help to evaluate which web technologies are used to make the dynamic website work. From there, we can investigate how the data can be accessed programmatically. For example, we might detect that a JavaScript program embedded in the webpage is querying additional data from the server whenever we scroll down in the browser and that all this additional data is transmitted in XML (before being embedded in the HTML). We then can figure out how the data is exactly queried from the server (e.g., how to build a query URL) in order to automate the extraction of data directly. The question then becomes how we can implement all this in R. In short, the following three steps can get us started:
- Which web technologies are used?
- Given a set of web technologies, how can we theoretically access the data?
- How can we practically collect the data with R?
This section gives insights into some of the web technologies frequently encountered when scraping data from dynamic websites and how to deal with them in R. As pointed out above, this is not a complete treatise of all relevant techniques to scrape data from dynamic websites. Thus, the techniques discussed here might not be relevant or sufficient in other cases.
7.2.1 Cookies
HTTP cookies are small pieces of data that help the server to recognize a client. Cookies are stored locally on the client side (by the web browser) when the server is submitting a website with cookies. During the further interaction with the same website, the browser is sending the cookie along other requests to the server. Figure 7.1) illustrates this point.
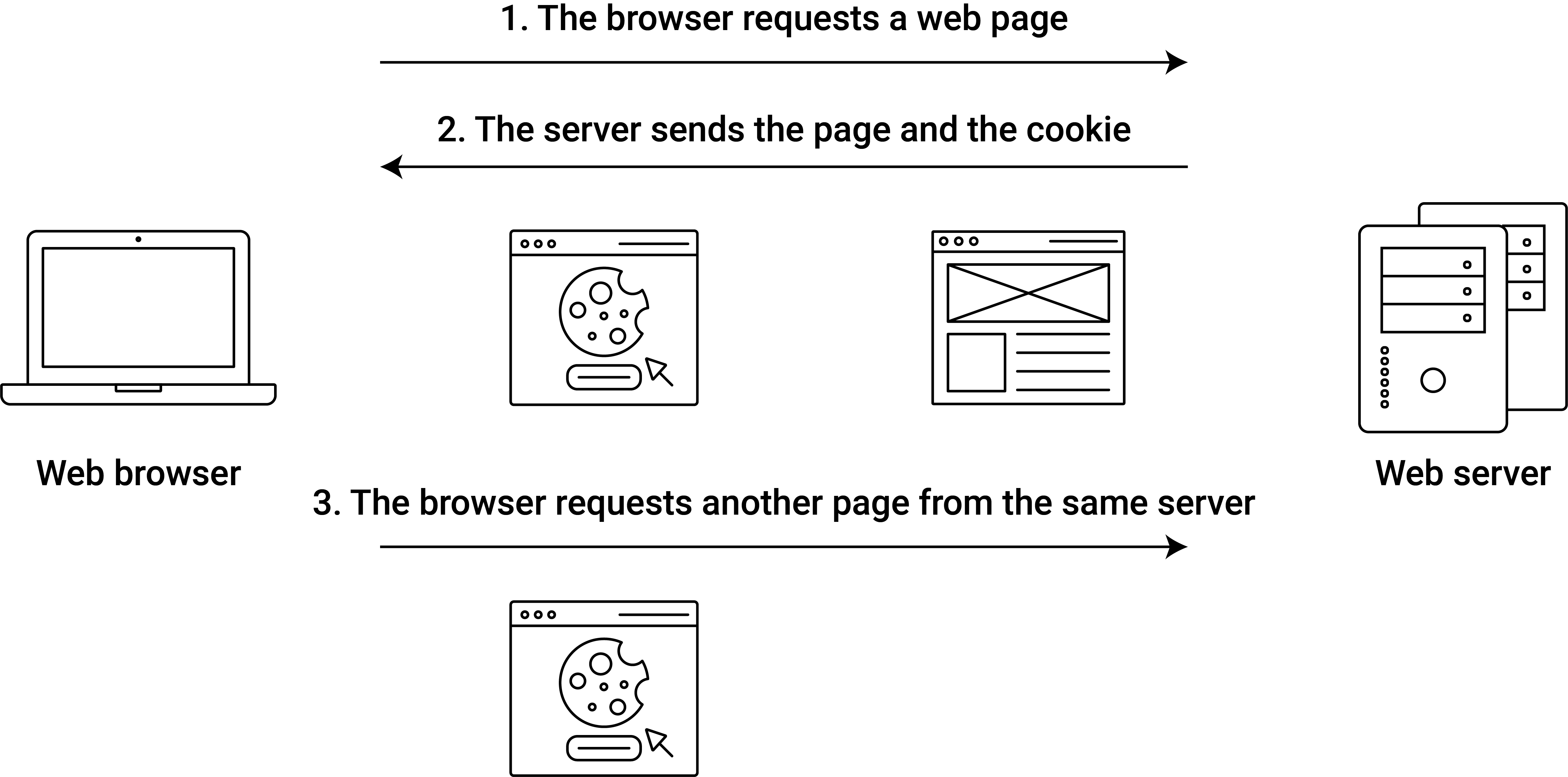
Figure 7.1: Illustration of HTTP cookie exchange.
Dynamic websites typically come with cookies. By identifying the user and her actions with the help of cookies, the server can keep track of what the user is doing and accordingly generate dynamic parts of the website. A most typical example of this are web shops where we might navigate through several pages, adding different items to the ‘shopping cart’. Once we click on the shopping-cart symbol a new webpage is created dynamically, showing us the cart’s ‘content’. Obviously, if another user would simultaneously visit the website and add other items to the cart, she would see a different page when clicking on the shopping cart. Similarly, if we would visit a web shop with our browser, add some items to the shopping cart, have a look at the shopping cart, and then try to scrape the content of it via R by copy/pasting the URL of the cart’s webpage, the result would likely be inconsistent with what we see in the browser. The reason is that the usual webscraping techniques visited in previous chapters do not automatically take into account cookies. That is, if we want to scrape a webpage that is dynamically generated based on cookies, we have to make sure that R is sending the cookies along with the URL that points to the server-side script generating the page (as the web browser would do automatically in such a case). In the following code example we explore how we can work with cookies in R.19
The code example implements a scraper that selects items (books) in the www.biblio.com web shop, adds them to the shopping cart, and scrapes the webpage representing the content of the shopping cart. The example builds on the previously used R packages rvest and httr.
From inspecting the website, we note how URLs to search for books are built.20 By inspecting the source code of the website we further learn that the dynamic generation of the webpage presenting the shopping cart content is triggered by sending a GET request with the URL http://www.biblio.com/cart.php.
########################################
# Introduction to Web Mining 2017
# 7: Programmable Web II
#
# Book Shopping with R
# U.Matter, November 2017
########################################
# PREAMBLE -------
# load packages
library(rvest)
library(httr)
# set fix variables
SEARCH_URL <- "https://www.biblio.com/search.php?keyisbn=economics"
CART_URL <- "https://www.biblio.com/cart.php"We first initiate a ‘browser session’ with rvest’s html_session() function. The returned R object not only contains the HTML document sent from the server but also information from the HTTP header, including cookies, which we can inspect with cookies().
# INITIATE SESSION -----
# visit the page (start a session)
shopping_session <- html_session(SEARCH_URL)## Warning: `html_session()` was deprecated in rvest 1.0.0.
## ℹ Please use `session()` instead.# have a look at the cookies
cookies(shopping_session)[, 1:5]## domain flag path secure
## 1 #HttpOnly_.www.biblio.com TRUE / FALSE
## 2 #HttpOnly_.biblio.com TRUE / FALSE
## expiration
## 1 2028-02-23 20:58:51
## 2 2023-02-25 20:58:51From inspecting the source code of the webpage we know that items are added to the shopping cart by means of an HTML form. We thus extract the part of the search results containing these forms.
# look at the html forms to add items to the cart
form_nodes <- html_nodes(shopping_session, xpath = "//form[@class='add-cart ']")
# inspect extracted forms
form_nodes[1:2]## {xml_nodeset (2)}
## [1] <form action="https://www.biblio.com/cart.php" m ...
## [2] <form action="https://www.biblio.com/cart.php" m ...From this we learn that if one form is submitted, it actually submits a book id. Thus if we want to add an item to the shopping cart via R, we need to submit such a form with a book-id number set as bid value. Therefore, we (a) store the structure of these forms in an R object (via html_form()) and (b) extract all the book ids from the search results.
# SUBMIT FORMS ----------
# extract one of the forms
form <- html_form(form_nodes[[1]])
# extract the book ids
bid_nodes <- html_nodes(shopping_session, xpath = "//input[@name='bid']/@value")
bids <- html_text(bid_nodes)The form template and the ids are sufficient to programmatically fill the shopping cart. We do this by iterating through all bids, setting the bid value to the respective value (with set_values), and then submitting the form (via submit_form()). Importantly, we submit these forms with the same session, meaning submit_form() will make sure that the relevant cookies of this session are sent along.21
# add books to the shopping cart
for (i in bids[1]) {
form_i <- set_values(form, bid = i)
names(form_i$fields)[4] <- "" # account for the fact that the form button has no name attribute
submit_form(shopping_session, form_i, submit = "")
}Finally, we scrape the content of the shopping cart. Note that instead of simply requesting the page CART_URL is pointing to, we use jump_to() with the already established shopping_session. This ensures that the GET request is issued with the cookies of this session.22
# open the shopping cart
cart <- jump_to(shopping_session, CART_URL)## Warning: `jump_to()` was deprecated in rvest 1.0.0.
## ℹ Please use `session_jump_to()` instead.# parse the content
cart_content <- read_html(cart)
# extract the book titles in the cart
books_in_cart <- html_nodes(cart_content, xpath = "//h4[@class='title']")
cat(html_text(books_in_cart)[1])## Medical Economics. September, 1939. The Business Magazine of the Medical Profession.It is straightforward to show that sending along the right cookies by using jump_to() with the same session in which we added the items to the cart is actually crucial. In order to demonstrate this, we simply start a new session and try the same as above, this time accessing the cart with the new session:
# initiate a new session
new_shopping_session <- html_session(SEARCH_URL)
# open the shopping cart
cart <- jump_to(new_shopping_session, CART_URL)
# parse the content
cart_content <- read_html(cart)
# extract the book titles in the cart
books_in_cart <- html_nodes(cart_content, xpath = "//h4[@class='title']")
cat(html_text(books_in_cart))In the new session (with new cookies) the shopping cart is still empty. Note that we use exactly the same URL. The only difference is that we submit the new cookies with the GET request (issued by jump_to()). Therefore, the server (correctly) recognizes that the session related to these new cookies did not involve any items being added to the shopping cart by the client.
7.2.2 AJAX and XHR
AJAX (Asynchronous JavaScript And XML) is a set of web technologies often employed to design dynamic webpages. The main purpose of AJAX is to allow the asynchronous (meaning ‘under the hood’) exchange of data between client and server when a webpage is already loaded. This means parts of a webpage can be changed/updated without actually reloading the entire page (as illustrated in Figure 7.2).
Figure 7.2: (ref:xhr
What w3schools.com calls “a developer’s dream” is a webscraper’s nightmare. The content of a webpage designed with AJAX cannot be downloaded by simply requesting an HTML document with an URL. Additional data will be embedded in the page as the user is scrolling through it in the browser. Thus what we see in the browser is not what we get when simply requesting the same webpage with httr. In order to access these additional bits of data automatically via R, we have to mimic the specific HTTP transactions between the browser and the server that are related to the loading of additional data. These transactions (as illustrated in Figure ?? are usually implemented with a so-called XMLHttpRequest (XHR) object. If we manage to control the exchange between client and server in the context of a dynamic website based on AJAX, figuring out how XHR works in this website is a good starting point.
The following code-example illustrates how the control of XHR via R can be implemented in the case of bloomberg.com. The goal is to scrape the ticker information shown on top of the website’s homepage.
########################################
# Introduction to Web Mining
# Bloomberg Ticker
########################################
# SETUP -------
# load packages
library(httr)
library(xml2)
library(rvest)
# 'TRADITIONAL' APPROACH -----
# fetch the webpage
URL <- "https://www.bloomberg.com/europe"
http_resp <- GET(URL)
# parse HTML
html_doc <- read_html(http_resp)
# extract the respective section according to the XPath expression
# found by inspecting the page in the broswer with Developer Tools
xpath <- './/div[@class="ticker-bar"]'
ticker_nodes <- html_nodes(html_doc, xpath = xpath)
ticker_nodes## {xml_nodeset (0)}This approach does not seem to be successful. We don’t get what we see in the browser. When tracing back the origin of the problem it becomes apparent that some of the html body displayed in the browser is missing. When we use the exact same xpath in the browser’s Web Developer Tools console, we get the expected result:
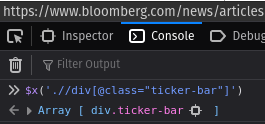
Figure 7.3: Screenshot of the Web Developer Tools’ console when extracting the bloomberg.com ticker information via XPATH.
By inspecting the network traffic with the Developer Tools’ Network panel, we notice traffic related to XHR. When having a closer look at these entries (via the ‘Response’ panel) we identify a get request with an URL pointing to https://www.bloomberg.com/markets2/api/tickerbar/global which returns exactly the data we were looking for in the webpage. A simple way to scrape the data based on this information seems to be to copy/paste this URL and rewrite the code chunk above accordingly. When simply pasting https://www.bloomberg.com/markets2/api/tickerbar/global into a new browser bar, we see, after all, the entire ticker data provided conveniently in a JSON file.
# mimic XHR GET request implemented in the bloomberg.com website
URL <- "https://www.bloomberg.com/markets2/api/tickerbar/global"
http_resp <- GET(URL)
# inspect the response
http_resp ## Response [https://www.bloomberg.com/tosv2.html?vid=&uuid=abc67731-b47d-11ed-a3f8-6e794d794447&url=L21hcmtldHMyL2FwaS90aWNrZXJiYXIvZ2xvYmFs]
## Date: 2023-02-24 19:58
## Status: 200
## Content-Type: text/html
## Size: 11.7 kB
## <!doctype html>
## <html lang="en">
## <head>
## <title>Bloomberg - Are you a robot?</title>
## <meta name="viewport" content="width=device-widt...
## <meta name="robots" content="noindex">
## <style rel="stylesheet">
## @font-face {
## font-family: BWHaasGroteskWeb;
## font-display: swap;
## ...Unlike when issuing the apparently same GET-request from within the browser, we don’t get the expected JSON file. Instead bloomberg.com is asking us whether we are robots. This illustrates that in modern websites that are partially based on webtechnologies like AJAX, the interaction between the browser and the server involve many more aspects than simple GET-requests with a URL. Under the hood, bloomberg.com is also verifying whether the request for the XHR-object has actually been issued from an authentic browser. Now, httr and related packages offer several ways to mimic these exchanges with the server in order to appear more like an authentic browser. However, at this point it might not be worth the while to invest so much time into developing such a sophisticated scraper, given that there is a reasonable alternative: Browser automation.
7.3 Browser Automation with RSelenium
Alternatively to analyzing and exploiting the underlying mechanisms that control the exchange and embedding of data in a dynamic website, browser automation can tackle web mining tasks at ‘a higher level’. Browser automation frameworks allow to programmatically control a web browser and thereby simulate a user browsing webpages. While most browser automation tools were originally developed for web developers to test the functioning of new web applications (by simulating many different user behaviors), it is naturally also helpful for automated data extraction from web sources. Particularly, if the content of a website is generated dynamically.
A widely used web automation framework is Selenium. The R package RSelenium (Harrison 2022) is built on top of this framework, which means we can run and control browser automation via Selenium directly from within R. The following code example gives a brief introduction into the basics of using RSelenium for the scraping of dynamic webpages.23
7.4 Installation and Setup
For basic usage of Selenium via R, the package RSelenium is all that is needed to get started. When running install.packages("RSelenium") the necessary dependencies will usually be installed automatically. However, in some cases you might have to install Selenium manually and/or install additional dependencies manually in order to make RSelenium work. In particular, it might be necessary to manually install Java accordingly (see here for detailed instructions). Depending on the operating system, the steps needed to install Selenium locally can differ. It therefore might be easier to run Selenium in a Docker container. See the instructions of how to run Selenium/RSelenium via Docker on Windows or Linux here and on Mac OSX here. In the code example below Selenium is run in a docker container. Also, see the official package vignette to get started with RSelenium.
Running RSelenium on your computer means running both a Selenium server and Selenium client locally. The server is running the automated browser and the client (here R) is telling it what to do. Whenever we use RSelenium we thus have to first start the Selenium server (here by starting the docker container that runs the selenium server). Once the server runs, we can initiate the client and connect to the Selenium server with remoteDriver(), and initiate a new browser session with myclient$open(). Now we control our robot browser through myclient.
# load RSelenium
library(RSelenium)
# start the Selenium server (in docker)
system("docker run -d -p 4445:4444 selenium/standalone-firefox")
# initiate the Selenium session
myclient <- remoteDriver(remoteServerAddr = "localhost",
port = 4445L,
browserName = "firefox")
# start browser session
myclient$open()7.4.1 First Steps with RSelenium
All methods (functions associated with an R object) can be called right from myclient. This includes all kind of instructions to guide the automated browser as well as methods related to accessing the content of the page that is currently open in the automated browser. For example, we can navigate the browser to open a specific webpage with navigate() and then extract the title of this page (i.e., the text between the <title>-tags) with getTitle().
# start browsing
myclient$navigate("https://www.r-project.org")
myclient$getTitle()## [[1]]
## [1] "R: The R Project for Statistical Computing"Navigating the automated browser in this manner directly follows from how we navigate the browser through the usual graphical user interface. Thus, if we want to visit a number of pages we tell it step by step to navigate from page to page, including going back to a previously visited page (with goBack()).
# simulate a user browsing the web
myclient$navigate("http://www.google.com/ncr")
myclient$navigate("http://www.bbc.co.uk")
myclient$getCurrentUrl()## [[1]]
## [1] "https://www.bbc.co.uk/"myclient$goBack()
myclient$getCurrentUrl()## [[1]]
## [1] "https://www.google.com/?gws_rd=ssl"Once a webpage is loaded, specific elements of it can be extracted by means of XPath or CSS selectors. However, with RSelenium, the ability of accessing specific parts of a webpage is not only used to extract data but also to control the dynamic features of a webpage. For example, to automatically control Google’s search function, and extract the respective search results. Such a task is typically rather difficult to implement with more traditional web mining techniques because the webpage presenting the search results is generated dynamically and there is thus not a unique URL where the page is constantly available. In addition, we would have to figure out how the search queries are actually sent to a Google server.
With RSelenium we can navigate to the search bar of Google’s homepage (here by selecting the input tag with XPath), type in a search term, and hit enter to trigger the search.
# visit google
myclient$navigate("https://www.google.com")
# navigate to the search form
webElem <- myclient$findElement('xpath', "//input[@name='q']")
# type something into the search bar
webElem$sendKeysToElement(list("R Cran"))
# type a search term and hit enter
webElem$sendKeysToElement(list("R Cran", key = "enter"))By default, Google opens a newly generated webpage presenting the search results in the same browser window. Thus, the search result is now automatically stored in myclient and we can access the source code with the getPageSource()-method. To process the source code, we don’t have to rely on RSelenium’s internal methods and functions but can also use the already familiar tools in rvest.
# scrape the results
# parse the entire page and take it from there...
# for example, extract all the links
html_doc <- read_html(myclient$getPageSource()[[1]])
link_nodes <- html_nodes(html_doc, xpath = "//a")
html_text(html_nodes(link_nodes, xpath = "@href"))[2]## [1] "https://mail.google.com/mail/&ogbl"This approach might actually be quite efficient compared to RSelenium’s internal methods. However, we can also use those methods to achieve practically the same.24
# or extract specific elements via RSelenium
# for example, extract all the links
links <- myclient$findElements("xpath", "//a")
unlist(sapply(links, function(x){x$getElementAttribute("href")}))[2]At the end of a data mining task with RSelenium we stop/close the Selenium server and Client as follows.
# be a good citizen and close the session
myclient$close()
# stop the docker container running selenium
# system("docker stop $(docker ps -q)")In practice, RSelenium can be very helpful when extracting data from dynamic websites as the procedure guarantees that we get exactly what we would get by using a browser manually to extract the data. We thus do not need to worry about cookies, AJAX, XHR, and the like, as long as the browser we are automating with Selenium deals with these technologies appropriately. On the downside, scraping webpages with RSelenium is usually less efficient and slower than a more direct approach with httr/rvest.25
Given the example code above, RSelenium can seamlessly be integrated in the generic web-scraper blueprint used in previous chapters. We can simply implement the first component (interaction with the web server, parsing of HTML) with RSelenium and the rest of the scraper with rvest et al.
References
This example is based on a similar code example in Munzert et al. (2014, 248). The original example code is based on other R packages.↩︎
The base URL for search queries is
http://www.biblio.com/search.php?with some search parameters and values (e.g.,keyisbn=economics).↩︎In this example, the form button to submit the data has no name attribute. By default
submit_form()is expecting the button to have a name attribute andset_values()would by default call the buttonunnamed(whichsubmit_formdoes not understand). Hence,names(form_i$fields)[4] <- ""sets the name of the button to an empty (""), and we tellsubmit_form()that the button we want to use has no (an empty) name (submit = "").↩︎There are several other ways of achieving the same in R (by rather ‘manually’ setting cookies). However, the shown functionality provided in the
rvestpackage is more user-friendly.↩︎The code example is partly based on
RSeleniumvignette on CRAN. For a detailed introduction and instructions of how to set up Selenium andRSeleniumon your machine, see theRSeleniumvignette on CRAN.↩︎Note that
RSeleniumandrvestrely on different XPath engines, meaning that an XPath expression might work in the functions of one package but not in the other.↩︎Note that scraping tasks based on Selenium can be speeded up by using several clients in parallel. However, the argument of computational efficiency still holds.↩︎