Chapter 11 Web Mining and Scientific Rigor
11.2 Reproduction/Replication
According to Science magazine, “REPLICATION—the confirmation of results and conclusions from one study obtained independently in another—is considered the scientific gold standard” (Jasny et al. 2011). Related to this concept (and often mixed up with it) is ‘reproduction’, usually referred to as the exact reproduction of the results (statistics, visualization), given the prepared data set. While the independent reproduction of results, given the final data set, can unveil errors/flaws in the statistical analysis of the original study, replication might additionally reveal problems in the data collection and data preparation of the original study.43 With the rise of Big Data (many variables and observations, often data in unusual/new formats), the preparation and cleaning of the raw data becomes a substantial part of an empirical study, often demanding special knowledge of data preparation techniques (‘data munging’).44 As long as the data source is still available in the same format (website-design has not changed, same API version still available), the replication of research based on automatically collected web data follows naturally. All that is needed is to inspect and run the web crawler/web scraper code and the code containing the data preparation used in the original study. In order to facilitate the reproducibility as well as replicability, it is helpful to organize the coding part of a research project right from the beginning according to two basic principles:
- Keep the pipeline in mind (if possible, seamless integration of all steps, from data collection to final results).
- Always consider making the final analysis public (including all code and data).
The following subsections give some practical advice of how this can be facilitated when working with R/RStudio.
11.2.1 Reproducible analyses with R/RStudio
11.2.1.1 Project, file structure, and file names
The starting point of organizing an analyses in order to make it more easily reproducible is to follow a clear and intuitive file-structure. First dedicate one folder/directory to the entire project (named after the project). Within the project folder, organize files into meaningful sub-directories. For example, keep all R-scripts needed for the project in one folder called code, and all data in a folder called data (maybe with a sub-folder raw and final), as well as folders for the final output (figures, tables). In addition, strictly follow a naming convention for all files. One quite intuitive rule is to follow the logic of the final product (usually a research paper) and name the intermediate products exactly after what they are (a raw data set: raw_data.csv, the final data set: final_data.csv, the first figure in the paper: figure_1.png, etc.). Then, organize and name the code after these parts as well. That is, raw_data.csv is generated when executing the code in raw_data.R, the code generating Figure 1 is stored in figure_1.R, etc. Moreover, apart from documenting the code well with comments within the R-files, keep a README.txt text-file in the top directory of the project where you document the overall project (short and in simple words).45 Finally, you can define the top-directory as an ‘RStudio-Project’ (File/New Project...). This is particularly helpful to navigate between different projects from within RStudio but also comes with many advanced RStudio features (see https://support.rstudio.com/hc/en-us/articles/200526207-Using-Projects for details on how to work with projects in RStudio). Figure 11.1 shows how such a project folder could look like in RStudio.
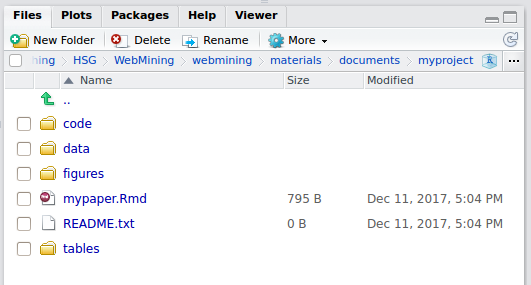
Figure 11.1: Project file structure.
11.2.1.2 R Markdown and knitr
RStudio comes with a version of Markdown called R Markdown, a lightweight markup language for making dynamic documents with R. Building on the file-structure described above, we can employ R Markdown to combine the entire study (text, data preparation, data analysis, and results) in one R Markdown document (e.g., mypaper.Rmd). We then can compile (‘knit’) this document and get either a nicely typeset pdf, HTML-file, or Word-document as a result. This means with one click, we can run the entire analysis pipeline and weave the results into the text.
11.2.2 Code and data repositories
The above outlined way of organizing all the parts of a project is very helpful for reproduction and replication even if the project is not intended to be made public. It helps the author to keep track of all aspects of the project when not working on it for a while or when just sharing it with a collaborator. Thus, it is very recommendable to follow such clear structures anyway. However, if the project is supposed to be made public for replication/reproduction purposes at some point, this structure should already be sufficient and nothing else needs do be done apart from actually publishing it. A most common way of doing so is to use a code repository such as GitHub or Bitbucket.46 Registration and basic storage space is for free (for public repositories). Using such repositories to facilitate reproducibility/replicability of research are particularly helpful as the repository can easily be documented (use Markdown for README-file), downloaded, and shared. Moreover, these repositories provide useful features with which coauthors or anybody who works with the code/data can interact with the repository owner (i.e., Wikis and Issues lists).
11.3 Sampling
Empirical research in the social sciences features both the proper description of data as well as statistical inference, i.e., inferring specific features of the population based on the features of a sample. The way the underlying data are collected as well as from what source they are collected can be very critical to the latter. As pointed out above, the fact of having relatively easy access to large-scale observational data makes web mining quite attractive. It is, however, important to keep in mind that web sources (and the way the data can be collected from them) also come with some constraints regarding key aspects of statistical inference. And those should be carefully considered when discussing the empirical results. This section points to some of these aspects and discusses their implications for the interpretation of results. Particularly, we look at the issues a sample based on automated data collection from the web typically has. The core problem domains are: selection bias, representativity, and external validity. All three domains tend to originate from the fact that the population we are interested in might not be perfectly reflected in the sample we collect from the web.
11.3.1 Representative samples
Say we want to infer the average age of the population of a country. Collecting information on everyone’s age would, however be too costly. We, therefore, only draw a sample of size \(N\) from that population and estimate the average age of the population via the average age of the people in the sample. Now, the way we collect the sample gets important. We might record the age of all inhabitants in a sizable town instead of the entire population. While our sample might be quite large then (say \(N=50,000\) ), there are good arguments that this sample would not be representative.
It might well be that young people are rather living in large towns than on the countryside. Then, we would underestimate the age of the overall population. Alternatively, we might randomly choose telephone numbers from the telephone book and call those people in order to register their age. The advantage of sampling randomly is that as long as \(N\) is large enough, we automatically should get a sample that is rather representative of the whole population. However, there is another issue. We only randomly sample from the population with telephone mainlines. Younger people might not use mainlines anymore but only their cellphones (and not register their number anywhere). Thus, by the technical means we use to collect this sample we systematically undersample the younger population and as a result we might overestimate the age of the overall population.
While having a large \(N\) is usually not an issue, there are two important parallels to these problems that can occur when collecting data from the web:
- Despite the apparently borderless reach of the World Wide Web, there might well be more subtle geographic restrictions to some websites or online platforms. Depending on what online source we use, we might thus (without realizing) restrict our sample to more or less specific geographic regions (as in the town-sample example above). At the end, Internet connections rely on a physical infrastructure (fiber-optic cables, copper cables, and some form of radio transmitters). Geographical aspects (topology, long distances between towns and villages, etc.) constrain the deployment of the infrastructure, leading to a situation where rural areas (particular in mountain regions) are not as well connected to the Internet as other regions. While in highly developed countries almost everybody has access to the Internet in one way or the other, there can still be substantial differences in speed, making, for example, YouTube a less attractive alternative to TV in rural areas than in cities.
- Some people might simply not use the Internet, join a particular social media platform, or write product reviews on Amazon. Whatever we collect from such sources, might then run into the same problems we have with surveying people over the telephone mainlines.
11.3.2 Selection bias
The problem with surveying people over the telephone mainline introduces what is generally referred to as ‘selection bias’. Due to the fact that random sampling only happens within the subgroup of the population living in a household with a telephone mainline, the sample is not a proper random draw from the overall population. Thus the problem is basically, that the sample is not representative. However, in applied econometrics the term selection bias often refers to a more specific problem that occurs when a researcher tries to assess the causal effect of a binary variable on an outcome variable (a so called ‘treatment effect’). Here, we do not just want to infer a statistic of the entire population such as the mean, but we want to infer whether there is a difference in the outcome variable between the ‘treated’ group and the ‘control group’. Thereby, the principal problem of selection bias occurs when the treated individuals differ from the individuals in the control group for reasons other than the treatment.
A typical situation where this could be an issue is Twitter. A research project might focus on public sentiment in the context of political elections. Consider an election between two candidates from different parties and we are interested in the effect of the victory of one of the candidates on the happiness of her supporters (and vice versa the effect of the loss of the other candidate on the happiness of her supporters).47 If the outcome of the race is really narrow, one might argue that which candidate won in the end is essentially a coin toss (nobody could predict the outcome with certainty), and the treatment is basically random. Let’s assume the researcher is measuring ‘happiness’ based on tweets from supporters of either candidate before and after the election day and compares the levels of happiness to the levels of happiness of the Twitter users in the neighboring jurisdiction. The researcher thus has to know who is supporting which candidate before the election in the jurisdiction where the election takes place and identify who is tweeting in the neighboring jurisdiction. Thus the overall tweet-stream has to be filtered according to geographic location (in either of the two jurisdictions) and for tweets identifying supporters of either candidate (only in the jurisdiction where the election takes place). Thus the raw sample can only be drawn from a subgroup of the population that uses geo-located tweets. While this means that the sample is not really representative of the population (both of Twitter users and the population over all), with regard to the type of research question at hand, this does not have to be a problem. That is, due to this lack of representativeness we do not automatically have a selection bias when inferring the treatment effect of a candidate’s victory on her supporters’ happiness. It might be reasonable to assume that the subgroup of Twitter users using geo-located tweets is very similar in the treatment jurisdiction (where the election takes place) and the control group (in the neighboring jurisdiction).
However, the fact that we also have to categorize who is a supporter of which candidate based on tweets before the election might introduce a serious problem. It might well be that Twitter users who write tweets which we can identify as being in favor of one or the other candidate might differ in many ways from users in the control group. The categorization of Twitter-users into supporters of either candidate based on what they tweeted before the election is a selection process which might introduce a substantial selection bias. The bias might actually depend on how we technically categorize the tweets as signals of a user being in favor or against a candidate. This technical problem of extracting tweets related to specific topics can lead to selection bias in various domains of research based on Twitter data (see, e.g., He and Rothschild (2016) for a recent discussion).
11.3.3 External validity
Even if a treatment effect can be properly identified with data collected from web sources, it might be problematic to extrapolate the findings to the general population/the real world. For example, can the contagion of information or emotions through online social network sites actually be compared to contagion of information or emotions in face-to-face interactions in real-world social networks? The problem here is not only that a sample cannot be drawn from the entire population because some might systematically not use social media etc., but also that the very people that use Twitter and Facebook might act very differently within this platforms than offline. In fact they might even automate some of their actions online (for example, retweeting tweets with certain contents). Moreover, in the case of Twitter, a substantial part of tweets might actually be generated by ‘bots’, fully automated twitter accounts, run by an algorithm.
References
Of course, this only holds if the data source is still available in the same format.↩︎
Note that there is hardly anything comparable in the offline world. Reproducing an entire data set would in most situations be as costly as the production of the original data set. There are thus hardly any incentives for researchers to replicate an entire study when all the data would have to be collected again manually.↩︎
Many renowned scientific journals in economics and more generally in the social sciences require that contributing authors provide the cleaned data set as well as the code containing the statistical analyses, however there are hardly any official requirements regarding replication of the data collection/data preparation parts.↩︎
This is often due to the fact that when preparing a large data set for analysis, researchers cannot check each observation (row) manually for potential coding mistakes or abnormal data entries in the raw data.↩︎
Note that if you follow the here suggested filename-convention, you don’t have to really document what R-file does what in the
README.txt. It will be enough to simply mention this convention, and the rest obviously follows.↩︎Core features (and one might argue the raison d’être) of these repositories is the version control system Git, and the facilitation of collaborative software development. An introduction to these features goes beyond the scope of this manuscript, though.↩︎
See, for example, Dodds et al. (2011) for how sentiment analysis of tweets is used to measure ‘happiness’.↩︎