Chapter 3 Web 1.0 Technologies: The Static Web
3.1 Communication Over the Internet: Clients and Servers
The web technologies relevant for most web data mining tasks are closely related to the so-called ‘client-server model’. In a client-server model, the ‘tasks’ of the system are partitioned between the providers of a resource (documents, data, services), called ‘servers’, and the requester of this resource, called ‘clients’. In the World Wide Web, the most common clients are web browsers, and the most common servers are web servers hosting websites. Thus, if you look up the latest news on www.nzz.ch, the browser on our device (iPhone, Laptop, etc.) is communicating with the web server of Neue Zuercher Zeitung, requesting the contents of the website, which is then provided by the server. This principle is in place for a broad variety of Internet applications (including Email, streaming services, online banking, etc.). When speaking about clients and servers we can refer to both the hardware and the software on either side. The former is often used to illustrate the client-server model graphically, such as in Figure 3.1.
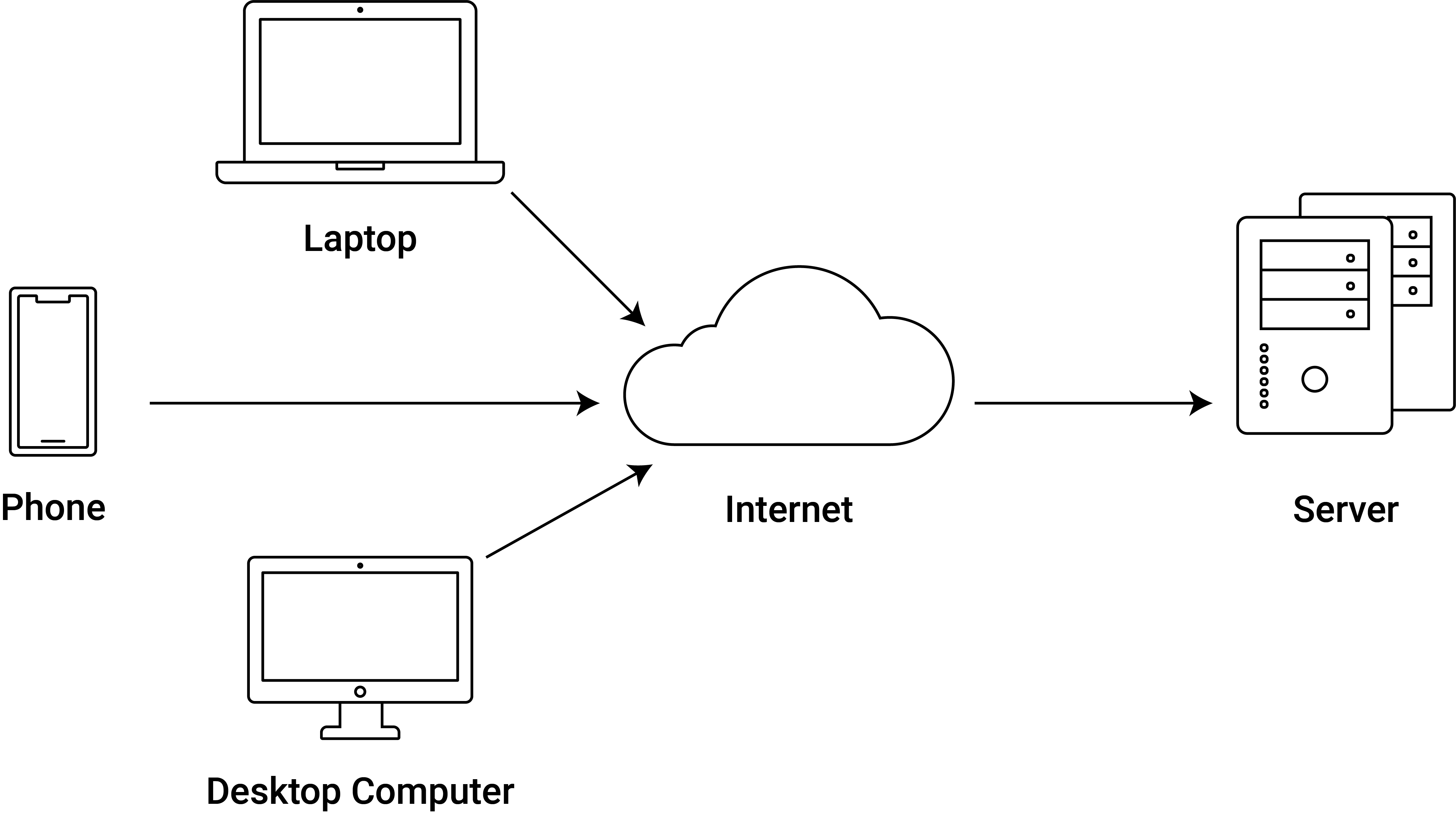
Figure 3.1: Client-Server Model illustration.
Note how the logic of the client-server model fits nicely into our web data mining framework of automatically collecting data from the web. We can use the same hardware we normally employ to access the Internet but simply replace the client software we usually use (the browser) with R. On the server side, hardly anything changes from that perspective. However, for many web scraping tasks we have to be aware that the server is programmed for interactions with web browsers. Thus a key aspect of learning the basics of web mining is how to control (and automate) the client side of client-server interactions. That is, we have to understand how client-server communication basically works from the client’s perspective.
3.2 HTTP: Rules of Communication
A very common standard that guides the exchange of documents over the web relevant for many basic web data mining tasks is the HyperText Transfer Protocol (HTTP).6 In principle, HTTP is a common way of formatting messages for communication sent over the Internet, combining a number of conventions of communication (adhered to by the clients and servers). These conventions define how communication between client and server starts/stops, how requests by a client and responses by the server look like, as well as how user authentication for documents with restricted access works.
The simplest HTTP method is the ‘GET request’ used by a client to simply ask a server (usually hosting a website) to send a specific webpage. A typical GET request to get the homepage of the University of St. Gallen’s website could look as follows:
GET /en/studium/aktuelles-zum-studium HTTP/1.1
Host: www.unisg.chThe first line is the ‘request line’ saying what the client wants to do (i.e., the method), GET, where the where the corresponding object/document is located (i.e., the path), /en/studium/aktuelles-zum-studium, and the version of the protocol it is using (version 1.1), HTTP/1.1. The second line and following lines constitute the ‘HTTP headers’, telling the server the hostname of the website where the requested document is (in this example only the mandatory host header). If everything goes well with the request, the HTTP response from the server would then start with:
HTTP/1.1 200 OK
Content-Type: text/htmlwhere the first line is the ‘status line’, indicating the protocol the server is using, then the numeric status code (200) and a short message (OK). The second line and some following lines are response headers, giving more information about the nature of the response. The line shown here is the most common response header (Content-Type), indicating what format the response body (the document) has (here: text/html which is typical for most webpages).7 All this (and more) is happening ‘under the hood’ when we type www.unisg.ch/en/studium/aktuelles-zum-studium into the address bar of our web browser. For the browser, the response headers are helpful to interpret the body of the response (how to parse and render the document in the browser window) and to decide what to do next (depending on the status code). Similarly, the HTTP response becomes an important aspect of the first step of a web scraping task. It helps the programmer to better control the web mining process, making the process more robust. For example, imagine a web scraper that visits several thousand websites, consisting of either HTML documents (webpages) or images (in Jpeg-format). The goal is to automatically extract the text from the webpages and save them in one folder and download the images in order to save them in another folder. We can make use of the HTTP response to make sure that our scraper knows what to do with the returned document (depending on the Content-Type), as well as make sure that we know in which cases something went wrong (depending on the status code). Being familiar with some of the most common HTTP response status codes as well as the typical content types is thus very helpful for the initial steps of web automation. There are 5 main categories of status codes, following Nolan and Lang (2014):
| Status | Category | Description |
|---|---|---|
100 |
Informational Continue | A 100 status code typically indicates that the communication is continuing and that more input is expected either from the client or the server. In most cases, we don’t have to bother about this code because the R package we use for our web mining tasks (and the underlying libcurl library) automatically take care of the next steps. |
200 |
Success | The request was successful. |
300 |
Redirection or Conditional Action | The server is telling us that the resource/document we request is actually in another location (maybe the website has been moved). Typically, the server also tells us in such cases what the new location is, thus we can tell our web data mining program to automatically follow that redirection. |
400 |
Client Error | An error occurred. Status codes in this category often occur in situations where the client requests something that does not exist (anymore) or that it is not allowed to access. |
500 |
Internal Server Error or Broken Request | An error occurred on the server side. However, this error can also show up when we automatically generate requests and send them from R (or any client other than a web browser), indicating an error in the request. |
The following table gives an overview of some of the frequently encountered status codes and what we might want our program to do when we encounter them:
| Code | Message | Action (?) |
|---|---|---|
301 |
Moved Permanently |
Replace the current URL with the new one, follow it, and continue. |
303 |
See Other |
If available, follow the other URL, and continue. |
403 |
Forbidden |
We won’t get data from this place, thus write to log file, and move on to next URL. |
404 |
Not Found |
The URL does not exist. Write to log file, move on to next URL. (This case should then be checked manually, we are potentially using an erroneous URL). |
408 |
Request Timeout |
Try again after a short moment, if still same status after several trials, write to log file, move on. |
For an extended list of HTTP status codes and their meaning, see the English language Wikipedia page on the issue (usually up to date and with helpful additional explanations) or the official memo of the Internet Engineering Task force (IETF).
Another common HTTP method besides GET is the POST request which allows the browser to send information to a server within the request (rather than in the URL). POST requests are often used when submitting a HTML form on a webpage. That is, in cases where the user has to type information into a form field and click a submit bottom instead of just clicking on a link on the page in order to get the desired data (or see the desired page in the browser). For example, if we want to log in to a webpage with protected content, such as the personal Facebook page, we are prompted to enter a username and password in some form fields on the websites’ login page. When we hit the ‘login’ button, we send a POST request that looks something like this:
POST /login.php HTTP/1.1
Host: www.facebook.com
...
email=username@example.com&pass=12345Note the similarities with the GET request. The structure is exactly the same, with the first line indicating the method (POST), the path (/login.php) and the protocol version (HTTP/1.1), and the following line with the HTTP headers. Here, the ‘body’ of the request contains the information submitted in the form (email=username@example.com&pass=12345).
We can illustrate the concept of client/server interaction and HTTP in the (Mac OS) terminal with a program called libcurl:
curl -I -s https://www.unisg.ch/en/studium/aktuelles-zum-studium | head -n 5## HTTP/2 301
## server: nginx
## date: Fri, 24 Feb 2023 19:58:33 GMT
## content-type: text/html
## content-length: 178Several of the R packages we will use throughout this course run on top of the lower level libcurl library. This substantially facilitates the writing of a short program to manage HTTP requests and responses as part of a web scraping exercise. Let’s have a look at the basics.
3.2.1 R exercise: basic HTTP requests and handling of responses
First, we load the R package httr which contains a couple of functions to handle HTTP requests and responses. We then use the package to send a simple GET request in order to fetch the University of St. Gallen’s webpage on degree course news, have a look at the components of the response, and extract the information about the Content-Type of the response.
3.2.1.1 HTTP requests and responses
In order to send a simple GET request and save the HTTP response in an R object, we can use the GET() function provided in the R package httr. If all we want is to send a simple GET request in order to fetch a webpage, all we need is the page’s address as an argument to the GET()-function.
# load packages
library(httr)
# send a HTTP GET request to fetch the webpage on degree course news
URL <- "https://www.unisg.ch/en/studium/aktuelles-zum-studium"
response <- GET(URL)
# look at the summary of the response provided by httr
response## Response [https://www.unisg.ch/de/studium/]
## Date: 2023-02-24 19:58
## Status: 200
## Content-Type: text/html; charset=utf-8
## Size: 145 kB
## <!DOCTYPE html>
## <html dir="ltr" lang="de">
## <head>
##
## <meta charset="utf-8">
## <!--
## ===================================================...
## Produced by: CS2 AG | Switzerland
## Contact: www.cs2.ch | Tel. +41 61 333 22 22 | info@...
## ===================================================...
## ...# have a look at the headers
headers(response)## $server
## [1] "nginx"
##
## $date
## [1] "Fri, 24 Feb 2023 19:58:33 GMT"
##
## $`content-type`
## [1] "text/html; charset=utf-8"
##
## $`last-modified`
## [1] "Fri, 24 Feb 2023 19:07:24 GMT"
##
## $etag
## [1] "W/\"63f90aec-235b6\""
##
## $`x-ua-compatible`
## [1] "IE=Edge"
##
## $`content-encoding`
## [1] "gzip"
##
## attr(,"class")
## [1] "insensitive" "list"All seems to have worked out well. Thus, in this case we could now continue and work on the content.
Similar to GET(), httr provides the high level function POST() to send POST requests to a web server. In the body argument of the function we can define the body of the HTTP POST request as text string.
# send a POST request to a page expecting POST
URL <- "http://httpbin.org/post"
POST(URL, body="This is the text submitted in this POST request")## Response [http://httpbin.org/post]
## Date: 2023-02-24 19:58
## Status: 200
## Content-Type: application/json
## Size: 518 B
## {
## "args": {},
## "data": "This is the text submitted in this POST r...
## "files": {},
## "form": {},
## "headers": {
## "Accept": "application/json, text/xml, applicati...
## "Accept-Encoding": "deflate, gzip, br, zstd",
## "Content-Length": "47",
## "Host": "httpbin.org",
## ...# Does not work with a GET request:
GET(URL)## Response [http://httpbin.org/post]
## Date: 2023-02-24 19:58
## Status: 405
## Content-Type: text/html
## Size: 178 B
## <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
## <title>405 Method Not Allowed</title>
## <h1>Method Not Allowed</h1>
## <p>The method is not allowed for the requested URL.</p>Note the domain we’ve used in this example: http://httpbin.org. This website provides a free HTTP request and response service to illustrate how HTTP works. It is primarily designed to help with the development of client-side HTTP libraries (programs) like the R package httr that we use in this example. However, the website is also a useful resource for learning what HTTP is by just looking at the examples through a browser.
3.2.1.2 Content types
To check the content type explicitly (and all other details in the headers of the HTTP response), we can use the function headers() and save the parsed HTTP headers in a variable called resp_h. From there, we can have a look at the respective header called ‘content-type’.
# extract the headers for further processing
resp_h <- headers(response)
# inspect the content type
resp_h$`content-type`## [1] "text/html; charset=utf-8"Let’s have a look at another example, where the content type is not html. In this example, we query data from the Swiss Federal Statistical Office, often providing data:
# request the data
URL <- "https://www.bfs.admin.ch/bfsstatic/dam/assets/16404549/master"
response_nse <- GET(URL)
# checkout the content type
resp_nse_h <- headers(response_nse)
resp_nse_h$`content-type`## [1] "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"As part of the first component of a web mining program (handling the communication with the servers) we might want to control the type of content that we receive when requesting data from hundreds or thousands of websites. A simple way of doing this is to write a function that checks whether the document we’ve fetched via an HTTP request is an HTML document or not.
# define the function
# x the response object
is_html <-
function(x){
grepl("text/html", x$`content-type`, fixed = TRUE)
}
# test it!
is_html(resp_h)## [1] TRUESuch a function can then be employed in a control statement (“if this… than do that…”) to make sure that the right kind of content is properly parsed for further processing in the second component of the web mining program (extraction of the relevant data).
3.3 URLs: Pointing to Documents on the Web
As you have probably noticed by now, all we actually need in order to get a document from the web via HTTP is an URL (Uniform Resource Locator), what we commonly call ‘link’ or a ‘web address’. In fact, URLs consist of several components that tell us something about what should be done with what resource where on the web. For example, the URL https://www.admin.ch/gov/en/start.html means “use HTTPS with host www.admin.ch and request the HTML document (webpage) start.html which is located in /gov/en/”. While handling URLs when manually ‘surfing’ the web via a web browser is straightforward (type or copy/paste it into the address bar, click on a link, etc.) it is crucial to know how to correctly parse and construct URLs when automatically extracting data from the web. Again, we have the necessary tools already available in the R package httr. First, let’s parse the URL from the example above in R and look at it’s components:
# have a look at the components of the URL
URL <- "https://www.admin.ch/gov/en/start.html"
parse_url(URL)## $scheme
## [1] "https"
##
## $hostname
## [1] "www.admin.ch"
##
## $port
## NULL
##
## $path
## [1] "gov/en/start.html"
##
## $query
## NULL
##
## $params
## NULL
##
## $fragment
## NULL
##
## $username
## NULL
##
## $password
## NULL
##
## attr(,"class")
## [1] "url"Similarly, we can construct an URL, given the components.
# define the components
components <- list(scheme="https", hostname="www.admin.ch", path="/gov/en/start.html")
class(components) <- "url"
# put them together
build_url(components)## [1] "https://www.admin.ch/gov/en/start.html"3.4 HTML and CSS: Content, Structure, and Design of Web Documents
The HyperText Markup Language (HTML) is commonly used to define webpages to be read in a web browser. Thus, HTML is predominantly designed for browsers, not for programmatic data collection with the aim of data mining or data analysis. In principle, HTML is used to annotate content and define the hierarchy of content in a document in order to tell the browser how to display (‘render’) this document on the computer screen.
3.4.1 Write a simple webpage with HTML
Let’s illustrate the basics of HTML with an example in which we write our own website. In order to do so we open a new text file in RStudio (File->New File->TextFile). On the first line, we tell the browser what kind of document this is with the <!DOCTYPE> declaration set to html. In addition, the content of the whole HTML document must be put within <html> and </html>, which represents the ‘root’ of the HTML document. In this you already recognize the typical annotation style in HTML with so-called HTML tags, starting with < and ending with > or /> in the case of the closing tag, respectively. What is defined between two tags is either another HTML tag, or the actual content. A HTML document usually consists of two main components: the head (everything between <head> and </head> ) and the body. The head usually contains meta data describing the whole document, for example, the title of the document:<title>hello, world</title>. The body (everything between <body> and </body>) contains all kind of specific content: text, images, tables, links, etc. In our very simple example, we just add a few words of plain text. We can now save this text document as mysite.html and open it in a web browser.
<!DOCTYPE html>
<html>
<head>
<title>hello, world</title>
</head>
<body>
<h2> hello, world </h2>
</body>
</html>From this example we can learn a few important characteristics of HTML:
- It becomes apparent how HTML is used to annotate/‘mark up’ data/text (with tags) in order to define the document’s content, structure, and hierarchy. Thus if we want to know what the title of this document is, we have to look for the
<title>-tag. - We see that this systematic structuring follows a nesting principle:
headandbodyare nested within thehtmldocument, at the same hierarchy level. Within thehead, one level lower, we define thetitle. In other words, thetitleis part of theheadwhich, in turn, is part of thehtmldocument. This logic, of one part being encapsulated in another part, is true in all correctly defined HTML documents. While this structure takes getting used to at first, you will soon learn to appreciate how this facilitates the systematic extraction of specific parts of data from HTML documents. - We recognize that HTML code expresses essentially what is what in a document. HTML code does thus not contain explicit instructions like programming languages do, telling the computer what to do. If a HTML document contains a link to another website, all that is needed, is to define (with HTML tag
<a href=...>) that this is a link. We do not have to explicitly express something like “if user clicks on link, send HTTP request to server, then parse response, …”. What to do with the HTML document is in the hands of the client software (web browser, or R).
These characteristics have important consequences for many web data mining tasks because they allow us to clearly distinguish between what a web designer/web programmer (someone who writes HTML pages for web browsers) has to know about HTML and what we as web miners have to know about it. Importantly, we do not have to know that much about what each HTML-tag stands for. Because, in most cases, we are not interested in how the content is exactly displayed on screen by a web browser. What we need to know is how to traverse and exploit the structure of a HTML document in order to systematically extract the specific content/data that we are interested in. We thus have to learn how to tell the computer (with R) to extract a specific part of an HTML document. And in order to do so we have to acquire a basic understanding of the nesting structure implied by HTML.
One way to think about an HTML document is to imagine it as a tree-diagram, with <html>..</html> as the ‘root’, <head>...</head> and <body>...</body> as the ‘children’ of <html>..</html> (and ‘siblings’ of each other), <title>...</title> as the child of <head>...</head>, etc. The following graph illustrates this point.
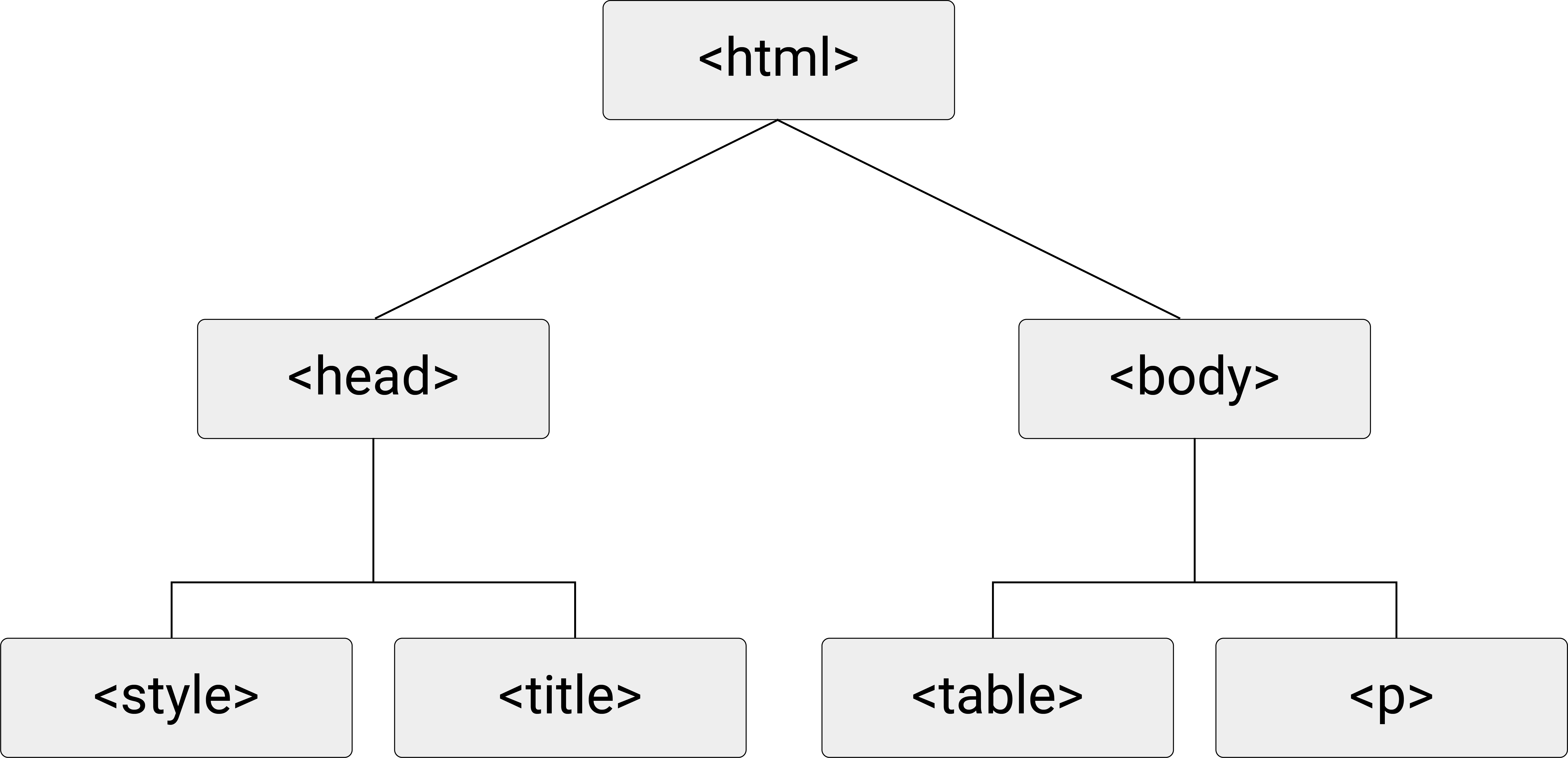
Figure 3.2: HTML (DOM) tree diagram.
3.4.2 CSS:
We can further design the looks of the webpage by adding ‘styles’ with another language called Cascading Style Sheets (CSS). CSS essentially defines how HTML tags should be displayed in the browser (if we don’t like the default rendering by the browser). While HTML is used to mark up web pages, or indicate their hierarchy and content, CSS is used to change the appearance of webpages. We can define styles directly in the head-section of an HTML document or in a separate CSS file (a so-called ‘stylesheet’) and then refer to it in an HTML page as shown in the code block below.
<!DOCTYPE html>
<html>
<head>
<link href="mystyle.css" rel="stylesheet"/>
<title>hello, world</title>
</head>
<body>
<h2> hello, world </h2>
</body>
</html>The file mystyle.css would then be stored in the same folder (on the server) as the webpage and could, for example, look like the code example below.
h2
{
font-size: 36px;
font-weight: bold;
}The defined CSS rule-set declares that all type 2 headers (<h2>) should be displayed in bold letters with a font size of 36 pixels.
Knowing the basics about CSS can become a helpful tool when scraping a webpage that heavily builds on CSS. In such a case a lot of the data might appear fairly well structured in the browser, although it is not so much in the actual HTML document. Web designers using CSS often rely on <div>-tags with specific class definitions and custom-made CSS styles that point to tags of such a class. This results in a HTML document consisting largely of nested <div>-tags. Traversing this structure might then be rather cumbersome (long and complex xpath expressions). However, if we know that the part of the data we are actually interested in is in each page of a website located in a <div>-tag of one particular class (due to the style choice of the web designer), we can directly extract it by exploiting the logic of how CSS works.
Let’s extend the HTML document above with some nested <div> tags to illustrate this point and save it as mysite2.html.
<!DOCTYPE html>
<html>
<head>
<link href="mystyle.css" rel="stylesheet"/>
<title>hello, world</title>
</head>
<body>
<h2> hello, world </h2>
<div class="content_type1">text text text text </div>
<div class="content_type1">other text
<div class="numbers">1, 2, 3</div>
</div>
</body>
</html>Now we extend the CSS file from above with some rule set definitions that declare how the contents of different <div> tags should be displayed in the browser depending on the respective class (set in the <div> tag).
h2
{
font-size: 36px;
font-weight: bold;
}
.content_type1
{
color: blue;
font-weight: bold;
}
.numbers
{
color: red;
}The use of class-specific CSS rule set definitions gives us more flexibility to design the webpage. A largely unintended consequence of it is that, at the same time, it substantially facilitates the extraction of specific content from large and complex websites with deep nesting structures. All we need is the class definition of the tags which contain the data of interest. How this can be exploited exactly will be covered in detail in the next two sessions.