Chapter 5 Web 2.0 Technologies: The Programmable/Dynamic Web
5.1 Technological Change in the Web
The web technologies discussed in the previous chapters have been around (at least in a very similar form) right since the beginning of the World Wide Web. While they are still the basis of most websites in one way or the other, new technologies are constantly extending and changing how data is presented and exchanged over the web. Similar to the older, basic web technologies like HTTP and HTML, we do not have to master all these new technologies in every detail in order to productively engage with the automated extraction of data. In fact, such an endeavor would require a whole curriculum on diverse computer languages, including Python, JavaScript, and SQL. What is important, though, is to gain a basic understanding of these newer web technologies in order to recognize \((i)\) which type of these technologies is used in a specific website we want to extract data from, \((ii)\) how we explore possible ways to access the data, given the technology used, and \((iii)\) what tools in R can be used to follow such a strategy (without having to learn a new language like JavaScript). For the first two points, the ‘developer tools’ provided in browsers such as Firefox and Chrome (with some extensions) do the job. Interestingly, in the context of these newer web technologies, everything related to the third point becomes either much simpler or substantially more complex, depending on the website at hand. In order to understand this, we have to understand what has changed in comparison to the old ‘Web 1.0’.
5.1.1 The web becomes dynamic
The core difference between the ‘old’ web and the ‘new’ web is a switch to the dynamic provision of web content. The adoption of many of the technologies we will discuss here is motivated by the idea of dynamically generating websites. In this context it is important to point out that the web initially (and foreseen by its father, Sir Tim Berners-Lee) was supposed to be static. URL/HTTP and HTML documents containing links to other HTML documents provide this static web. In order to look up a specific webpage under this paradigm, all we need is the URL pointing to the HTML-document that constitutes the webpage. Any user connected to the Internet could type this URL into the address bar of her browser and would see essentially the same result (unless the very document the URL is pointing to was changed by its author). As you might have experienced in your every-day use of the Internet, this is actually not anymore the case for a large number of websites. When you visit www.amazon.com from your own personal computer, you are likely to see other product recommendations than your colleagues, although all of you type in the exact same URL, apparently pointing to the exact same webpage. By and large this is due to the use of various modern web technologies to build the webpage. What you actually see in your browser is now often the result of a bunch of programs being executed (partly on the server side, partly on the client side) once you open a website in your browser, click on a link, or move your mouse over a website in the browser window. This can be nicely illustrated with the Firefox Developer Tools’ Network panel, a program that keeps track of all the web traffic coming through an active browser window: When opening the Network panel and then visiting www.nzz.ch, over a 150 HTTP requests are sent. However, only the first two represent the initial intention of downloading the webpage (HTML document), as it was in the ‘old web’.
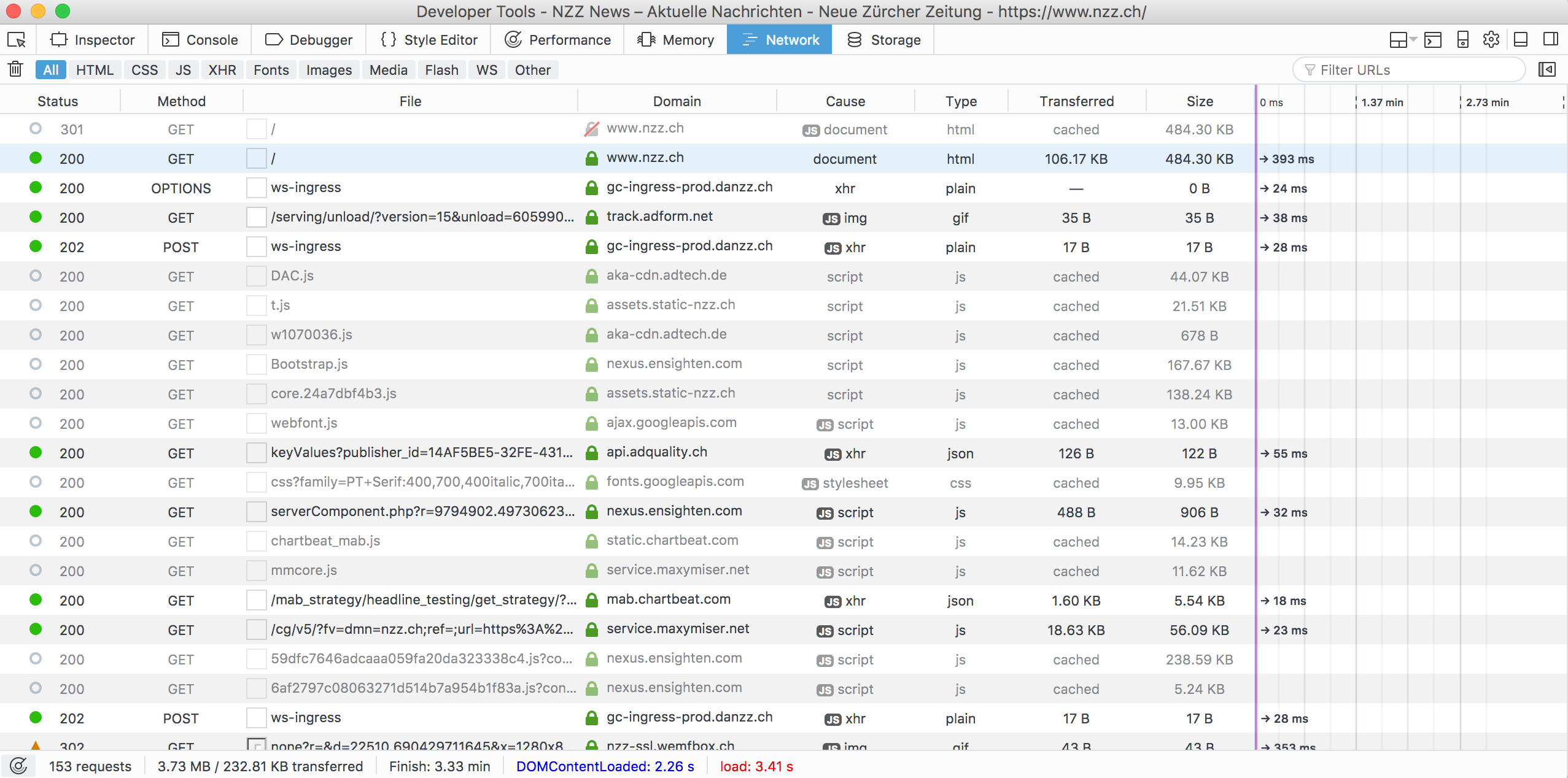
Figure 5.1: Network traffic recorded by Firefox Development Tools’ Network panel.
From inspecting the traffic recorded from this one page visit, it becomes apparent that many of the programs executed in the course of opening the website www.nzz.ch in our web browser, are in one way or the other related to online marketing. They either dynamically integrate adds in the page or record our clicking behavior (in order to optimize the former). However, even websites of non-profit organizations might rely on dynamically generating the pages, often with the aim of being more ‘user friendly’ (some design aspects of websites cannot be implemented with a static site), but also—sadly for people like us—with the aim of making it harder to automatically extract the data provided in the website.
5.1.2 Basic design of dynamic websites
While the client-server model is still part of modern web technologies, the tasks handled on both the server- and the client-side have become much more diverse than simply transferring requests and responses via HTTP. Client-side (‘front end’) applications (written, e.g., in JavaScript are often focused on features of a dynamic, interactive website that need to react ‘instantly’ when the user clicks on something, moves her mouse, or types something into a form field (such as drop-down menus, mouse-over effects, etc.). Server-side (‘back end’) applications are often used for the dynamic integration of data in a webpage. In such cases, the HTML documents constituting the website are generated ‘on-demand’ (e.g., via Django/Python) based on some webpage-templates and data stored in a SQL database, before it is sent to the client.
The real challenges for automated data collection from dynamic websites emerge when the dynamic site is relying on both sides, such as client-side JavaScript programs embedded in the header of a webpage that dynamically request data (or a service/algorithm) from the server, depending on what the user is clicking at/moving over in what is currently displayed in the web browser.12 Such websites introduce complexity to the web scraping tasks because the way they work and the way they are implemented is further removed from a situation in which the user explicitly directs a device to access specific content. As illustrated in the first part on web technologies, getting the desired content is closely related to URLs. Whether we click on a link in an HTML document rendered in a browser window or type it directly into a browser bar, the intention of the user is straightforwardly reflected in both what the user needs to know and how the technology assists her. Therefore, it is relatively easy to tell the computer (for example via R) how to do the same thing. In dynamic websites based on modern web technologies, the activities on the client side are further removed from the user’s explicit intentions and resemble rather a set of programs that surveil the user’s actions when browsing a website, issuing various GET and POST requests without having the user actively realizing it. Therefore, it becomes harder to automate what happens on the client side. So far, we have inspected a website’s source code in order to know how to extract the specific part of the website that we are interested in as properly formatted data. When dealing with automated data extraction from dynamic websites, we might have to inspect that website’s source code in order to understand how to request the data we see on the screen in the first place.
Figures 5.2 and 5.3 illustrate the difference between the old/conventional model of a web application and a web application based on AJAX/JavaScript as it is frequently encountered for a dynamic/interactive website.
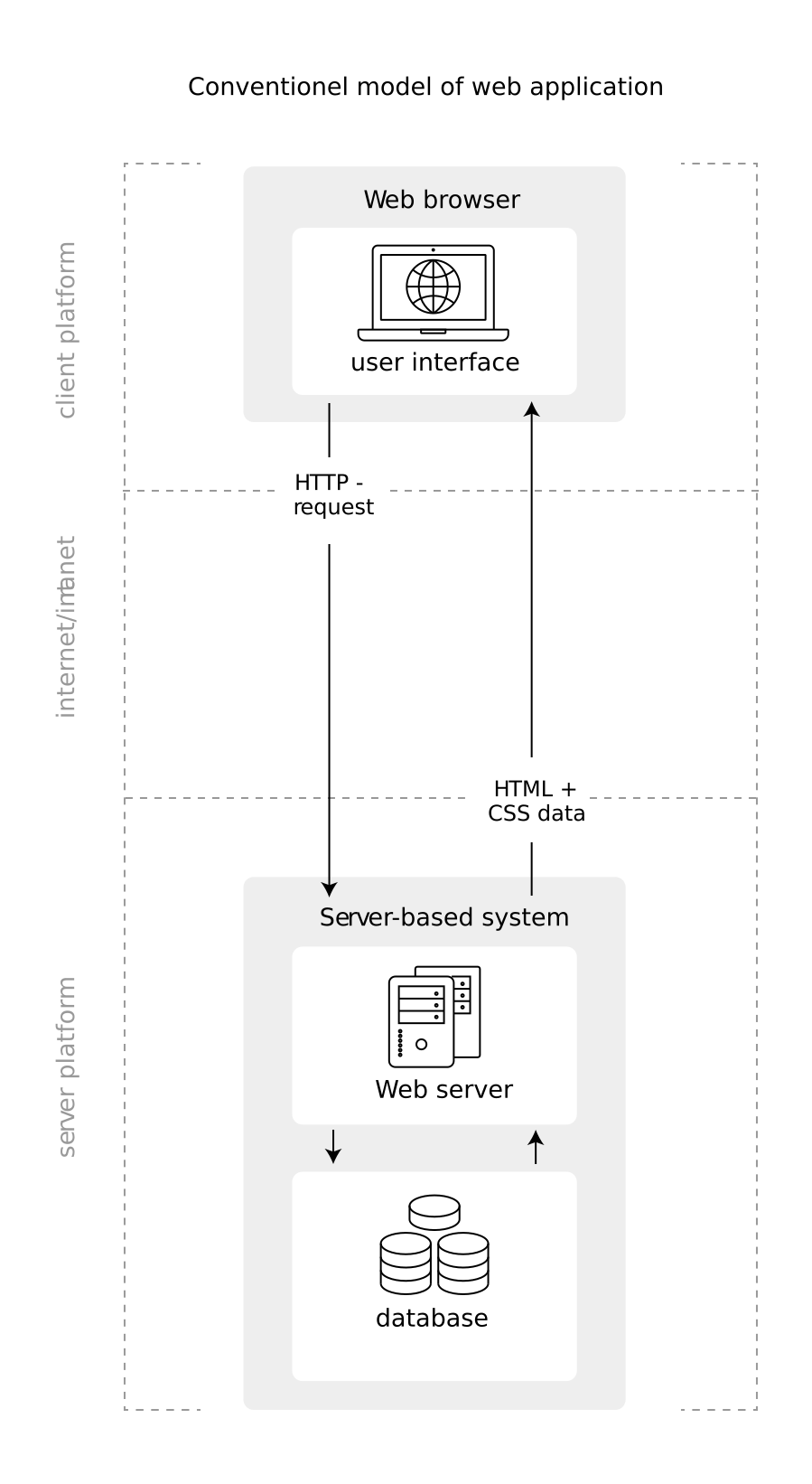
Figure 5.2: Illustration of the conventional web application model (often used for static websites).
In the conventional model, the client
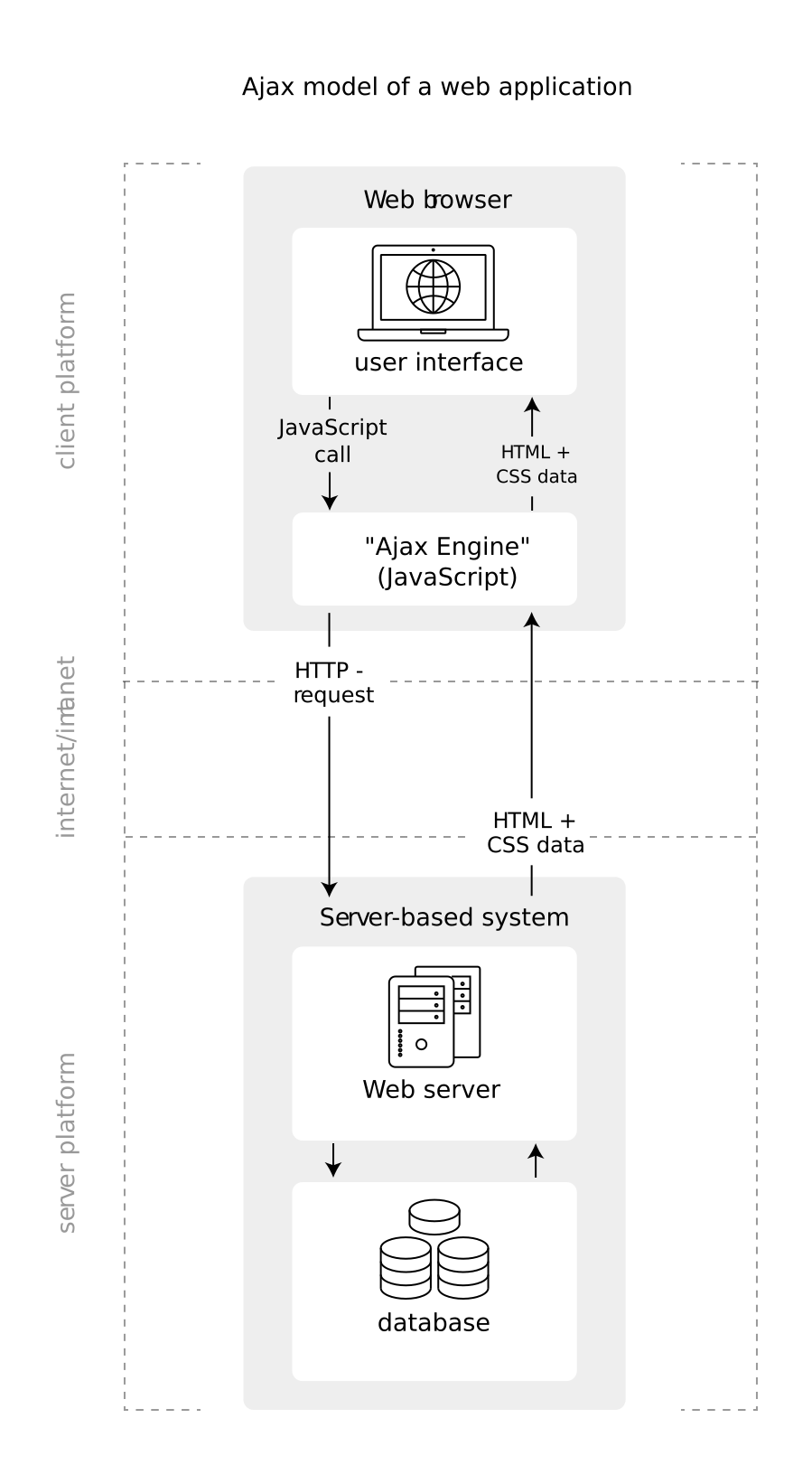
Figure 5.3: Illustration of a web application model based on AJAX/JavaScript (often used in dynamic websites).
Note how in an AJAX/JavaScript-based website, a lot of the GET requests involved in the data transfer between server and client is not directly issued from the user interface but from a program written in JavaScript that reacts to what the user does in the interface. Also, note the difference between the two models regarding how the HTML/CSS data enters the user interface (the browser). In a dynamic website based on AJAX/JavaScript, the actual HTML document rendered in the Browser is constructed dynamically on the client side. This means that when we are trying to extract data from it, following the blueprint for a web scraper discussed in the previous chapters, we likely encounter substantial discrepancies between what we see in the browser and what has been parsed in R.13
5.2 Key Aspects for Automated Web Data Extraction
5.2.1 Building blocks of dynamic websites
Modern web technologies can–for the purposes of automated web data collection–be categorized into two broad categories: 1. Computer languages used to write server- or client-side programs to send HTTP requests, query data bases, and construct pages (Django/Flask/Python/Jinja, JavaScript/AJAX, SQL, etc.). 2. File format conventions, such as JSON (JavaScript Object Notation), or markup languages for web data, such as XML (Extensible Markup Language).
Regarding the first category, we can largely ignore all that is happening on the server side (mainly because we cannot actually see the code constituting the back end of a web application). However, we have to understand the very basics of the server side programs running a dynamic website in order to understand how our scraper can mimic a user clicking her way through the website to automatically retrieve the desired data. The second category we have to understand better simply because we directly extract web data in these formats in the context of dynamic websites.
5.2.1.1 JavaScript
JavaScript programs are either directly embedded in the header section of an HTML page or are downloaded from the server along the download of the HTML page (as files with a .js ending). In the latter case, a link in the header section of the HTML document usually points to the .js-file. As a high-level programming language designed to program the behavior of websites, JavaScript has a lot of pre-defined functions that can be directly embedded in the body-part of a HTML-document. These are arguably the simplest instances of JavaScript frequently encountered in webpages.
In order to illustrate the basic mechanisms of webpages with JavaScript, we implement a JavaScript-enriched dynamic website, in which the content changes when the user clicks on a form button. We do so by extending the simple (HTML-only) webpage developed in previous chapters:
<!DOCTYPE html>
<html>
<head>
<title>hello, world</title>
</head>
<body>
<h2> hello, world </h2>
</body>
</html>We now extend this HTML document in order to create a very simple dynamic website based on JavaScript. The JavaScript function to access (and potentially manipulate) parts of a webpage is document.getElementById() and takes arguments referring to HTML-elements (identified via the id attribute of an HTML tag). In order to make our simple website dynamic, we thus have to enable JavaScript to recognize what element of the page we want to change. We do this by simply giving the tag around the content we want to change an id: <h2 id="dynamic_part"> hello, world </h2>. In addition, we need an element in the webpage that can trigger the JavaScript function. A form button (<button>...</button>) is a straightforward way to do this. The code of the dynamic version of our webpage thus looks as follows:
<!DOCTYPE html>
<html>
<head>
<title>hello, world</title>
</head>
<body>
<h2 id="dynamic_part"> hello, world </h2>
<button
type="button"
onclick='document.getElementById("dynamic_part").innerHTML = "Hello, JavaScript!"'>
Click here for a change!
</button>
</body>
</html>What the code in the <button>-tag essentially means is: “Once the user clicks on this button (onclick=), execute document.getElementById("dynamic_part").innerHTML = "Hello, JavaScript!"”. The JavaScript code means “get the HTML-tags in this document with the id ‘dynamic_part’, and change the HTML content between the tags to 'Hello, JavaScript!'”. We can save this webpage locally and open it in Firefox to test the dynamic function.
Now let’s parse the webpage with R and extract the content of the website as text-string:
# load packages
library(xml2)
library(rvest)
# parse the local webpage, extract its content
webpage <- read_html("documents/dynamic_website.html")
content_node <- html_node(webpage, xpath=".//*/h2")
html_text(content_node)## [1] " hello, world "Note how this diverges from what we see in the browser (and in the source code). JavaScript dynamically changed the content of the HTML document. But, the original document which we read into R did not change. The first thing to be learned here is how to recognize when this is happening in a web scraping task, and then to locate the origin of the discrepancy of what we see in the browser and what we get as a result in R.
In the relatively simple example above, it is rather easy to come up with a work-around solution once we realize that the content we see in the browser is actually also contained in the webpage we read into R. It is only hidden in the <button>-tag’s onclick-attribute. In many instances of dynamic websites this is not the case, though. The JavaScript program executed locally might instead issue a GET-request to a web server which then returns the data that gets dynamically embedded in the webpage (as outlined in Figure ??). In such cases we have to figure out what this GET request looks like in order to automate the data extraction task. In fact, this is exactly what we did as part of the Wikipedia scraper.14 Wikipedia’s search function works through a combination of JavaScript programs running on the client side and PHP programs on the sever side. Once the user starts typing something into the search field, the client side programs constantly ‘listen to’ what the user types and constantly send what has been typed to the program running on the server which in turn runs the submitted characters against a data base (also running on a server) and returns a list of terms related to what the user just typed (you can easily observe all this in the Firefox Development Tools). Once the user hits enter, another program captures the entered term, constructs a URL/GET request that is then sent to the server. The latter is the feature we could exploit for our scraper by simply inspecting which GET request was related to the actual webpage content (the HTML-document).
5.2.1.2 JSON and XML
Embedding data in an HTML document dynamically via AJAX/JavaScript or a similar web technology demands a certain convention regarding the format of the data. Two widely accepted conventions are XML and JSON. While the syntax of XML and JSON clearly differ, they share a common feature that becomes important when extracting data from such a document. Similar to HTML, both inhibit a nested (or tree-like) data structure.
5.2.1.2.1 XML
XML is a generalization of the HTML principle and was designed to store and transport data (and intended to be both human- and machine-readable). A XML-document thus looks quite similar to an HTML document. However, in XML the tags can be freely defined and serve as annotation of the actual data between the tags. The following XML document, containing a small customer data base, illustrates this point:
<?xml version="1.0" encoding="UTF-8"?>
<customers>
<person>
<name>John Doe</name>
<orders>
<product> x </product>
<product> y </product>
</orders>
</person>
<person>
<name>Peter Pan</name>
<orders>
<product> a </product>
</orders>
</person>
</customers>The tags describe what kind of data they contain (i.e., like column-names in a table), the nesting structure reveals to what higher-level entity a lower-level entity belongs: persons are customers, each person has a name and orders, orders can consist of one or several products etc.
Luckily for us, there are several XML-parsers already implemented in R packages specifically written for working with XML data. We thus do not have to understand the XML syntax in every detail in order to work with this data format in R. The already familiar package xml2 (Wickham, Hester, and Ooms 2021) (automatically loaded when loading rvest) provides the read_xml() function which we can use to read the exemplary XML-document shown above into R.
# load packages
library(xml2)
# parse XML, represent XML document as R object
xml_doc <- read_xml("documents/customers.xml")
xml_doc## {xml_document}
## <customers>
## [1] <person>\n <name>John Doe</name>\n <orders>\n ...
## [2] <person>\n <name>Peter Pan</name>\n <orders>\n ...The same package also comes with various functions to access, extract, and manipulate data from a parsed XML document. In the following code example, we have a look at the most useful functions for our purposes (see the package’s vignette for more details).
# navigate through the XML document (recall the tree-like nested structure similar to HTML)
# navigate downwards
# 'customers' is the root-node, persons are it's 'children'
persons <- xml_children(xml_doc)
# navigate sidewards
xml_siblings(persons)## {xml_nodeset (2)}
## [1] <person>\n <name>Peter Pan</name>\n <orders>\n ...
## [2] <person>\n <name>John Doe</name>\n <orders>\n ...# navigate upwards
xml_parents(persons)## {xml_nodeset (1)}
## [1] <customers>\n <person>\n <name>John Doe</nam ...# find data via XPath
customer_names <- xml_find_all(xml_doc, xpath = ".//name")
# extract the data as text
xml_text(customer_names)## [1] "John Doe" "Peter Pan"5.2.1.2.2 JSON
In many web applications, JSON serves the same purpose as XML (programs running on the server side are frequently capable of returning the same data in either format). An obvious difference between the two conventions is that JSON does not use tags but attribute-value pairs to annotate data. The following code example shows how the same data can be represented in XML or in JSON (example code taken from https://en.wikipedia.org/wiki/JSON):
XML:
<person>
<firstName>John</firstName>
<lastName>Smith</lastName>
<age>25</age>
<address>
<streetAddress>21 2nd Street</streetAddress>
<city>New York</city>
<state>NY</state>
<postalCode>10021</postalCode>
</address>
<phoneNumber>
<type>home</type>
<number>212 555-1234</number>
</phoneNumber>
<phoneNumber>
<type>fax</type>
<number>646 555-4567</number>
</phoneNumber>
<gender>
<type>male</type>
</gender>
</person>JSON:
{"firstName": "John",
"lastName": "Smith",
"age": 25,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021"
},
"phoneNumber": [
{
"type": "home",
"number": "212 555-1234"
},
{
"type": "fax",
"number": "646 555-4567"
}
],
"gender": {
"type": "male"
}
}Note that despite the differences of the syntax, the similarities regarding the nesting structure are visible in both formats. For example, postalCode is embedded in address, firstname and lastname are at the same nesting level, etc.
Again, we can rely on an R package (jsonlite) (Ooms 2014) providing high-level functions to read, manipulate, and extract data when working with JSON-documents in R. An important difference to working with XML- and HTML-documents is that XPath is not compatible with JSON. However, as jsonlite represents parsed JSON as R objects of class list and/or data-frame, we can simply work with the parsed document as with any other R-object of the same class. The following example illustrates this point.
# load packages
library(jsonlite)
# parse the JSON-document shown in the example above
json_doc <- fromJSON("documents/person.json")
# look at the structure of the document
str(json_doc)## List of 6
## $ firstName : chr "John"
## $ lastName : chr "Smith"
## $ age : int 25
## $ address :List of 4
## ..$ streetAddress: chr "21 2nd Street"
## ..$ city : chr "New York"
## ..$ state : chr "NY"
## ..$ postalCode : chr "10021"
## $ phoneNumber:'data.frame': 2 obs. of 2 variables:
## ..$ type : chr [1:2] "home" "fax"
## ..$ number: chr [1:2] "212 555-1234" "646 555-4567"
## $ gender :List of 1
## ..$ type: chr "male"# navigate the nested lists, extract data
# extract the address part
json_doc$address## $streetAddress
## [1] "21 2nd Street"
##
## $city
## [1] "New York"
##
## $state
## [1] "NY"
##
## $postalCode
## [1] "10021"# extract the gender (type)
json_doc$gender$type## [1] "male"5.3 APIs and the Programmable Web
In the context of web data mining, JSON and XML are particularly often encountered when extracting data from a website that is interacting with a so-called web API (Application Programming Interface) on the server side. Web APIs facilitate the integration of web data in various websites by a clearly defined request-response message system (usually via URLs and HTTP). The standardized exchange of data facilitates the development of dynamic websites which, as outlined above, rely on programs that request and embed data in the webpages ‘under the hood’ (without the user explicitly requesting the data through the browser interface). Figure 5.4 illustrates this point (also note how this seamlessly integrates with the modern web application framework illustrated in Figure 5.3).
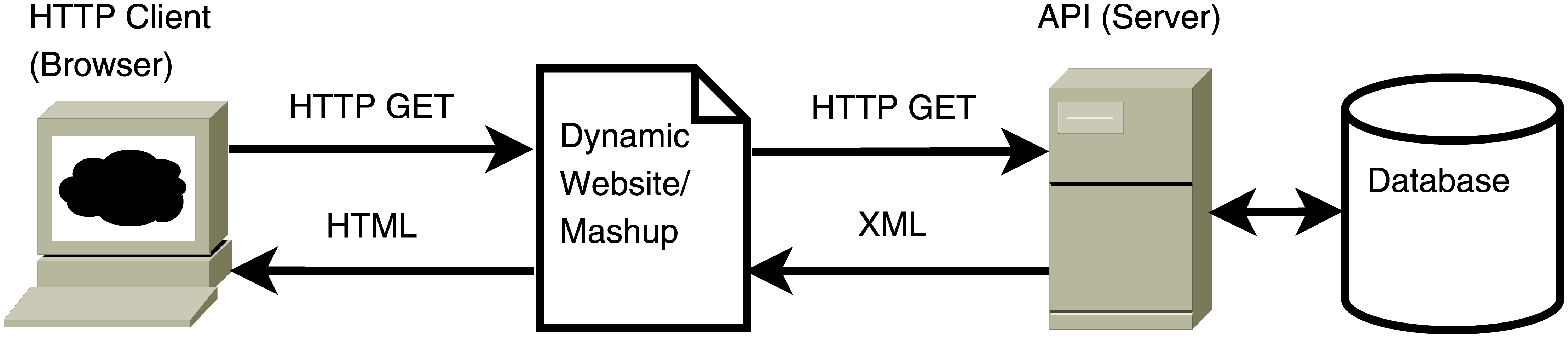
Figure 5.4: Illustration of browser requesting a dynamic website with data embedded from a web API. Source: Matter and Stutzer (2015).
Certain types of web APIs open new opportunities for automated data extraction in cases where web scraping would be very cumbersome.15 In simple terms, the manifestation of these opportunities is that instead of writing web scrapers that mimic the users/visitors of a website, we can write programs that hook into the web data on a lower level. That is, instead of writing a program that requests data from an API and embeds it in an HTML document on the client side (as a web programmer would do), we can write a program that sends exactly the same kind of requests to the API. However, instead of embedding the data in a webpage to be rendered by a browser, we directly reformat and store the data of interest for statistical analysis in a research project (as illustrated in Figure 5.5).
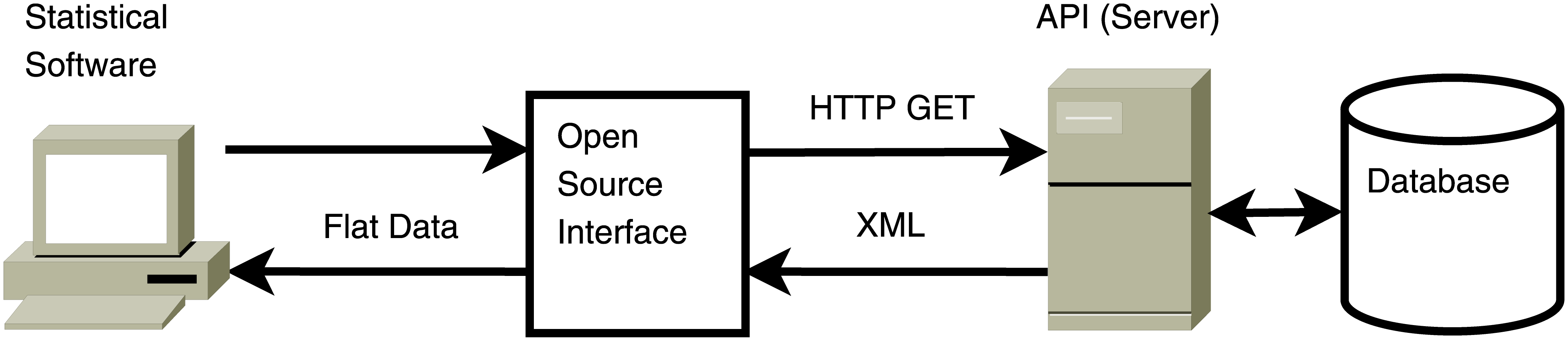
Figure 5.5: Illustration of a program running in a statistical computing environment requesting data from a web API. Source: Matter and Stutzer (2015).
The change from the conventional web application model based on HTTP/HTML to the web application model applied for dynamic websites constitutes both challenges and opportunities for web data mining. On the one hand, writing a scraper that extracts data directly from a dynamic webpage can become substantially more complex. On the other hand, the new web application model offers the opportunity to directly query the data in a clearly defined format, optimized for the exchange over the web (such as XML and JSON). Whether one or the other case is relevant for a specific web mining task largely depends on the availability and accessibility of a web API. In the latter case, an R program for the automated extraction of data from the web is not only simpler to write and more robust. In various cases that are of great interest for economists and social scientists in general, such programs are already made available in R packages, making the web data mining task even simpler.
References
Such applications are often implemented with a web technology called AJAX (Asynchronous JavaScript and XML).↩︎
A typical feature of dynamic websites frequently encountered and clearly resembling the challenges due to these new technologies for web scraping tasks, is the automated extension of webpages when scrolling down (e.g., the Facebook or LinkedIn feeds). We can easily observe the various
GETrequests happening under the hood with the Firefox Developer Tools’ Network panel when scrolling down in a Facebook or LinkedIn page.↩︎By inspecting the Wikipedia search field, we’ve noticed that some information is sent to a PHP script. Then, by inspecting the network traffic while executing a search, we’ve identified the URL pointing to this script as well as how we have to add parameters to that URL in order to construct valid searches.↩︎
This is particularly the case for so-called RESTful APIs.↩︎