Chapter 8 Web Mining Programs
Web data mining, in its most basic form, is the creation of programs that automatically download web pages. The majority of the simpler programs and scripts we’ve implemented thus far can be referred to as ‘web scrapers’ or simply ‘scrapers,’ referring to the task of automatically extracting (scraping) specific data from a webpage. Scrapers are typically designed to extract data from a specific website or a clearly defined set of websites (for example, scrape the headlines from all Swiss newspaper homepages). More sophisticated web data mining programs deal with situations in which we want to automatically extract data from the Web without having a predefined set of pages to visit. As a result, these programs include an algorithm that traverses the Web, jumping from one website to the next, extracting links to other websites, and storing information from the visited pages in a local repository. These programs are commonly referred to as crawlers, spiders, or robots (all terms refer essentially to the same concept). Crawlers follow the same basic blueprint as web scrapers (HTTP interaction, data extraction, and data storage), but they are more autonomous and dynamic in the sense that they constantly update the list of URLs to be visited. This dynamic aspect necessitates some careful implementation planning.
8.1 Applications for Web Crawlers
Crawler development in computer science reaches a level of sophistication that far exceeds the requirements of typical social science research. In fact, a key industry of the modern Internet is based on crawlers: search engines. A search engine, such as Google’s, must index (and thus physically store) the entire (open) Web in order to function properly. The crawler at Google is constantly traversing, storing, and indexing all webpages it can find. When we search for something on www.google.com, we are actually searching on Google’s copy of the Web. The URLs in the search results then point to the corresponding webpage on the real Web. Because webpages on the Internet change frequently, Google’s crawler must constantly traverse the Web at high speeds to keep the index current. Otherwise, the returned search results may contain URLs that point to defunct websites. A high-performance crawler is not only a sophisticated piece of software; it also relies on a massive hardware infrastructure to achieve the required performance.
Crawlers for search engines may be the most impressive in terms of technology. In other contexts, many smaller, less sophisticated crawlers are used. Examples of such applications include:
- Business intelligence and marketing: collect information about competitors, competitors’ products and prices.
- Monitor websites in order to be automatically notified about changes.
- Harvest email addresses for spamming.
- Collect personal information for phishing attacks.
- Dynamic generation of websites with contents crawled from other websites.
Crawlers are useful tools for academic research in the social sciences for a variety of reasons. They can function as custom-built search engines, traversing the Web to collect specific content that would otherwise be difficult to find. They are a logical progression from a simple scraper focused on a single website. If the research question is specifically about the link structure of specific websites, they are the primary tool of trade. That is, if we want to investigate which pages are linked to which others in order to construct a link network. The study by Adamic and Glance (2005), who investigated how political blogs linked to each other during the 2004 U.S. election, is an illustrative and well-known example of the latter. The authors show that there is a clear political divide in the United States blogosphere, with bloggers sympathizing with one of the two major parties (Republicans/Democrats) preferentially linking to blogs/blog-entries associated with the same party and rarely linking to blogs that support the opposing party’s position (see Figure 8.1). Their study received a lot of attention, partly because it was interpreted as providing evidence for Cass Sunstein’s famous theses that the Internet creates “filter bubbles” and “echo chambers,” fostering political polarization. (Sunstein 2002).
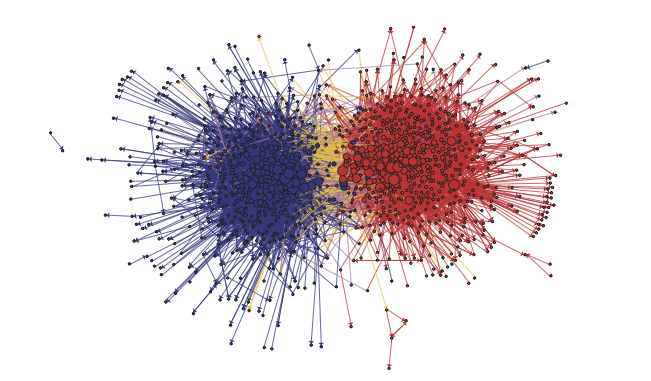
Figure 8.1: Graph depicting the community structure of political blogs. Nodes are blogs, edges are links between blogs. The colors indicate political orientation, red for conservative and blue for liberal. The size of nodes reflects the number of in-links. Source: Adamic and Glance (2005).
8.2 Crawler Theory and Basic Concepts
A Web crawler is fundamentally a graph traversal algorithm or graph search algorithm, which is the process of visiting each node in a graph (network), where nodes represent webpages and edges represent hyperlinks. The algorithm then begins with one or more nodes/pages (referred to as “seeds”), extracting each of the URLs to other pages and adding those URLs to the list of URLs to be visited (the “frontier”), before moving on to the next page. Figure 8.2 shows how such an algorithm works in general.
Figure 8.2: Illustration of a graph traversal algorithm (breadth-first).
A key aspect of the crawling algorithm is the order in which new URLs are picked (‘de-queued’) from the frontier to be visited next. This, in fact, determines the type of graph traversal algorithm implemented in the crawler program. There are two important paradigms of how the next URL is de-queued from the frontier that matter in practical applications of web crawlers for relatively simple web mining tasks: first-in-first-out and different forms of priority queue. The table below compares the two approaches regarding implementation and consequences (following Liu (2011, 311 ff)).
| Property | First-in-First-Out | Priority Queue |
|---|---|---|
| Type of Crawler | Breadth-First Crawler | Preferential Crawler |
| Implementation | Add new URLs to tail of frontier, pick next URL to crawl from head of frontier. | Keep the frontier ordered according to the estimated value of the page (according to some predefined criteria, e.g. words occurring in the URL etc.), always pick URL from head of the frontier. |
| Consequence | Crawling is highly correlated with the in-degree of a webpage (the number of links pointing to it). The result is strongly affected by the choice of seeds (initial set of URLs in frontier). | Result is highly dependent on how the ordering of the frontier is implemented. |
Without additional specifications, both types of crawlers could (theoretically) continue traversing the Web until they had visited all webpages on the Internet. This is unlikely to be required for any standard crawler application in the social sciences. As a result, in most practical applications of a simple crawler that adheres to either of the two principles described above, a stopping criterion will be defined, bringing the crawler to a halt after reaching a certain goal. This predetermined goal can be quantitative or qualitative. A data collection task to investigate the link structure surrounding a specific website (e.g., an online newspaper) might, for example, be restricted to a certain degree of the link network. That is, we define the crawler as only visiting pages within the website’s domain and all links pointing directly from within the website’s domain to other pages outside the domain (but not to those pointing from outside the domain to even further pages, etc.). The number of pages visited could also be used to stop the crawler. Such crawling rules are typically implemented by limiting the type of URLs (depending on domain) or the number of URLs that can be added to the frontier, and/or by keeping track of all previously visited pages.
A crawler does nothing more than traverse the Web by extracting links from newly visited pages and keeping track of pages already visited. In that case, the crawler’s goal is to collect information about the link structure itself. Any extensions to the content collection can then be added using scraping tasks that are executed for each page visited. In the most basic case, the ‘scraping’ task can simply consist of saving the entire webpage to a local repository. Other tasks could include extracting only specific parts of the visited pages (tables, titles, etc.) and saving them in a predefined format. In short, any of the scraping exercises from previous chapters could be implemented as part of a crawler in some way. Thus, the scraping component of a Web crawler can be viewed as a separate component, a module that can be developed and optimized independently (independently of how the graph traversal part of the crawler is implemented).
Figure 8.3 illustrates a basic crawler that simply stores the visited webpage in a local repository.
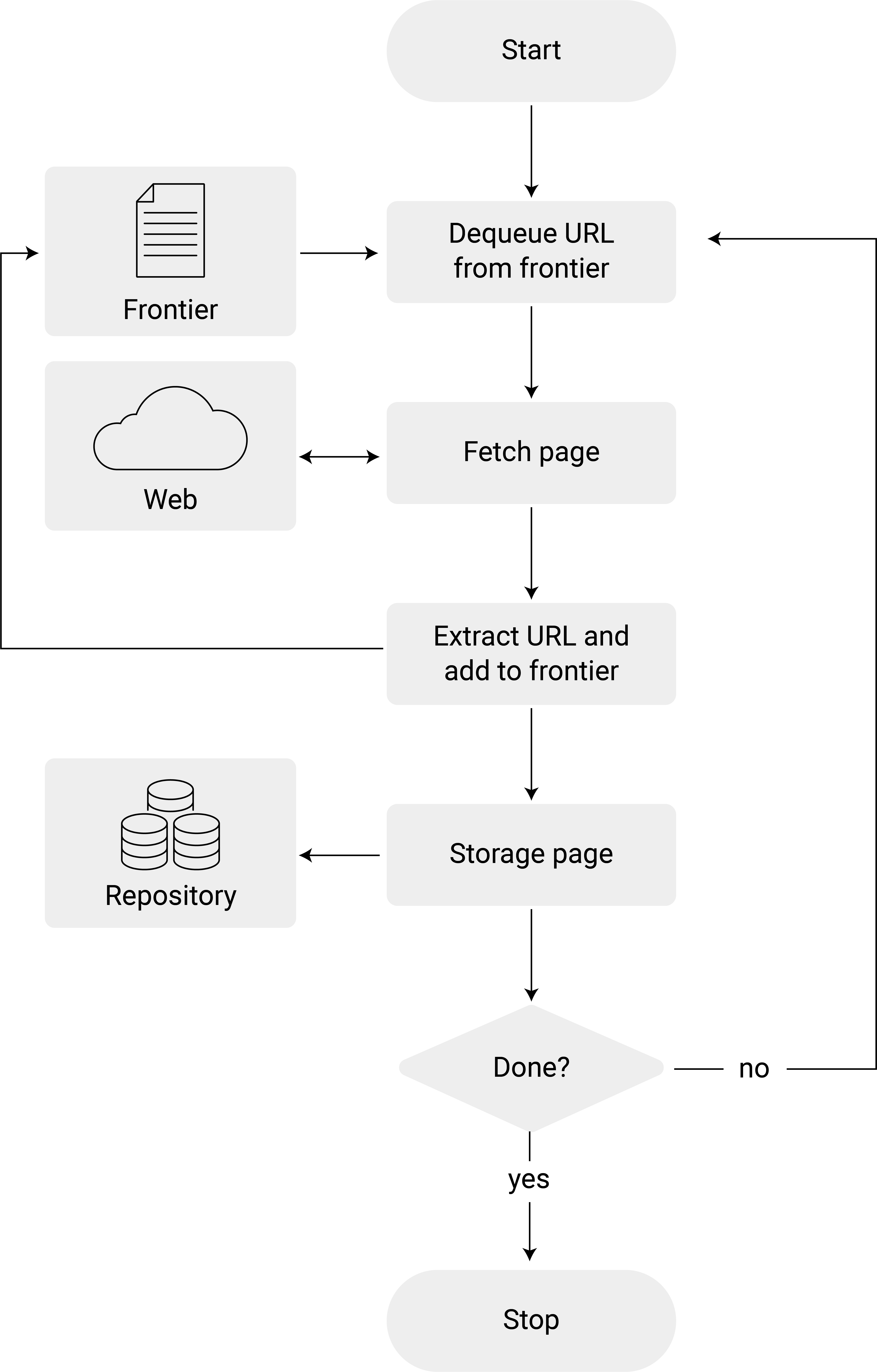
Figure 8.3: Flow chart of a basic Web crawler, following Liu (2011, 313).
8.3 Practical Implementation
Following the flow chart and discussion of web scraping aspects of a crawler discussed above, we will look at the practical implementation of the components that make up a well-functioning breadth-first crawler. Critical aspects of implementation are discussed and implemented in R for each component. For the purposes of the exercise, we create a crawler that navigates the link structure surrounding a specific Wikipedia page until the frontier is reached or 100 pages are visited.
8.3.1 Initiating frontier, crawler history, and halt criterion
The starting point of any crawler is to define the initial set of URLs to be visited (the seed, i.e, the initial frontier). Note that if the frontier consists of more than one URL, the order of how the URLs are entered into the frontier matter for the crawling result.
# PREAMBLE -----
# load packages
library(httr)##
## Attaching package: 'httr'## The following object is masked from 'package:NLP':
##
## contentlibrary(rvest)
library(xml2)
library(Rcrawler)
# initiate frontier vector with initial URLs as seeds
frontier <- c("https://en.wikipedia.org/wiki/George_Stigler",
"https://en.wikipedia.org/wiki/Paul_Samuelson")
# initiate empty list to keep track of crawler history (visited pages)
crawl_hist <- matrix(ncol = 2, nrow = 0)
colnames(crawl_hist) <- c("visited_URL", "found_URLs")
# initiate control variables
# set limit of pages to be visited
n <- 10
# initiate control variable for frontier
frontier_not_empty <- TRUE
# initiate counter variable
counter <- 18.3.2 Dequeue first URL, fetch webpage
This component has essentially the same implementation issues as the ones encountered with simple web scrapers (first and second component of the scraper blueprint): communicate with the server via HTTP, control and parse the response.
# DEQUEUEING AND FETCHING OF WEBPAGE ---
# dequeue URL from frontier
current_URL <- frontier[1]
# fetch page via HTTP
resp <- GET(current_URL)
# parse HTML
html_doc <- read_html(resp)8.3.3 Extract links, canonicalize links add to frontier
This component contains the same functionality as the second component of a simple scraper. However, due to the nature of the crawling algorithm, the emphasis is on how to extract URLs and add them to the frontier. As a result, URL ‘canonicalization’ is critical for the crawler’s robustness/stability. The goal of URL canonicalization is to ensure that URLs added to the frontier function properly and are not duplicated. The most important aspect of this is to ensure that URLs are absolute and do not contain any unnecessary parts or formatting (remove standard ports and default pages, coerce to lower case characters, etc.). For this task, we make use of the LinkNormalization()-function provided in the Rcrawler package (Khalil 2018).
# LINK EXTRACTION -----
# extract all URLs
links_nodes <- html_nodes(html_doc, xpath = ".//a")
URLs <- html_attr(links_nodes, name = "href")
# clean URLs
# remove anchors
URLs <- URLs[!grepl("#", URLs, fixed = TRUE)]
# remove NAs
URLs <- na.omit(URLs)
# canonicalize URLs, only keep unique entries
URLs <- unique(LinkNormalization(links = URLs, current = current_URL))
# add to tail of frontier (first-in-first-out -> breadth first)
frontier <- c(frontier, URLs)8.3.4 Update crawler history (and data extraction)
All this very simple crawler does is to keep track of the visited links and which URLs were found on the visited page. Anything related to data extraction and storage that goes beyond the necessary extraction of URLs would be implemented in this part of the crawler. For example, we could save the entire page (html_doc) to a local text-file for further analysis later on.
# DATA PART -----
# create log entry
log_df <- data.frame(visited_URL = current_URL, URLs_found = URLs)
# add to crawler history
crawl_hist <- rbind(crawl_hist, as.matrix(log_df))8.3.5 Update control variables
Finally, at the last stage of one crawling iteration, we have to update the variables critical to the control statements that state when the crawler has to stop or continue.
# CONTROL PART ----
# update frontier (remove the currently visited URL)
frontier <- frontier[-1]
# update control variables
frontier_not_empty <- length(frontier) != 0
# display status on screen:
# cat(paste0("Page no. ", counter, " visited!"))
# update counter
counter <- counter + 18.3.6 The crawler loop
All that is left to be done in order to have a fully functioning web crawler, is to put the components together in a while-loop. With this loop we tell R to keep executing all the code within the loop until the stopping criteria are reached. Note that crawlers based on while loops without wisely defined control statements that keep track of when to stop, could go on forever. Once a crawler (or any other program based on a while-loop is implemented) it is imperative to test the program by setting the control variables such that we would expect the program to stop after a few iterations if everything is implemented correctly. If we were to implement a crawler that we expect to visit thousands of pages until reaching its goal, it might be hard to get a sense of whether the crawler is really iterating towards its goal or whether it is simply still running because we haven’t correctly defined the halting criterion.
#######################################################
# Introduction to Web Mining 2017
# 8: Crawlers, Spiders, Scrapers
#
# Crawler implementation:
# A simple breadth-first web crawler collecting the
# link structure up to n visited pages.
#
# U.Matter, November 2017
#######################################################
# PREAMBLE -----
# load packages
library(httr)
library(rvest)
library(Rcrawler)
# initiate frontier vector with initial URLs as seeds
frontier <- c("https://en.wikipedia.org/wiki/George_Stigler",
"https://en.wikipedia.org/wiki/Paul_Samuelson")
# initiate empty list to keep track of crawler history (visited pages)
crawl_hist <- matrix(ncol = 2, nrow = 0)
colnames(crawl_hist) <- c("visited_URL", "found_URLs")
# initiate control variables
# set limit of pages to be visited
n <- 10
# initiate control variable for frontier
frontier_not_empty <- TRUE
# initiate counter variable
counter <- 1
# START CRAWLING ITERATION ----
while (frontier_not_empty & counter <= n) {
# DEQUEUEING AND FETCHING OF WEBPAGE -----
# dequeue URL from frontier
current_URL <- frontier[1]
# fetch page via HTTP
resp <- GET(current_URL)
# parse HTML
html_doc <- read_html(resp)
# LINK EXTRACTION -----
# extract all URLs
links_nodes <- html_nodes(html_doc, xpath = ".//a")
URLs <- html_attr(links_nodes, name = "href")
# clean URLs
# remove anchors
URLs <- URLs[!grepl("#", URLs, fixed = TRUE)]
# remove NAs
URLs <- na.omit(URLs)
# canonicalize URLs, only keep unique entries
URLs <- unique(LinkNormalization(links = URLs, current = current_URL))
# add to tail of frontier (first-in-first-out -> breadth first)
frontier <- c(frontier, URLs)
# DATA PART -----
# create log entry
log_df <- data.frame(visited_URL = current_URL, URLs_found = URLs)
# add to crawler history
crawl_hist <- rbind(crawl_hist, as.matrix(log_df))
# CONTROL PART ----
# update frontier (remove the currently visited URL)
frontier <- frontier[-1]
# update control variables
frontier_not_empty <- length(frontier) != 0
# display status on screen:
cat(paste0("Page no. ", counter, " visited!\n"))
# update counter
counter <- counter + 1
}## Page no. 1 visited!
## Page no. 2 visited!
## Page no. 3 visited!
## Page no. 4 visited!
## Page no. 5 visited!
## Page no. 6 visited!
## Page no. 7 visited!
## Page no. 8 visited!
## Page no. 9 visited!
## Page no. 10 visited!