Chapter 9 Crawler Implementation
The simple breadth-first crawler implemented in the previous chapter can be extended and refined in various ways. Depending on the data extraction tasks foreseen for the crawler, a lot of the refinement might go into the ‘data part’ which can be extended with all kind of scraping and data manipulation techniques (extract only specific components of a webpage, store all the text contained in the crawled webpage after removing all HTML-tags, etc.). Beyond the implementation issues discussed in the context of web scraping, there are some additional crawler-specific implementation issues to be considered.
9.1 Time management
Crawlers might be running for many hours to complete a web mining task. Some specifications of the implementation should be focused on how the crawler can be managed in terms of time. The following list gives a brief overview of what aspects and techniques might be relevant regarding the time management of a crawler:
9.1.1 Iteration time
Particularly if a crawler is focused on one or a few specific domains with a lot of pages, it is important to keep in mind that the crawler might not be welcome if it uses up too much of the server’s bandwidth and thereby slows down the server and potentially upsets the normal users that visit the respective pages with a browser. As a rule of thumb, a crawler is considered ‘polite’ if it doesn’t send more than 10 requests per second to the same server (Liu 2011, 313). For simple sequential crawlers, as the one implemented above, the time passing between two requests essentially depends on how much processing is done in the data part of the crawler. If the processing/extracting of the data is very efficient (as in the example above), requests might be issued very frequently. In such cases, we can consider implementing a timeout between individual requests. That is, we can tell R after one crawling iteration to wait, e.g., 0.5 seconds until moving on with the next iteration. This can easily be implemented with the function Sys.sleep(). Thus, to pause our crawler for half a second after each iteration, we would have simply to add one line with Sys.sleep(0.5) after the last line within the while-loop. The following code chunk shows how this could be done by simply extending the CONTROL PART in the breadth-first crawler implemented during the last chapter.
# CONTROL PART ----
# update frontier (remove the currently visited URL)
frontier <- frontier[-1]
# update control variables
frontier_not_empty <- length(frontier) != 0
# display status on screen:
cat(paste0("Page no. ", counter, " visited!\n"))
# update counter
counter <- counter + 1
# take a break
Sys.sleep(0.5)Note that this would be the last step within the while-loop. That is, after each iteration of the loop, the loop would pause for half a second before going to the next iteration (dequeuing the next URL from the frontier).
9.1.2 Crawling intervals
The aim of a data mining task might be to repeatedly collect data from the same website. For example, we might want to collect data on the news coverage of a specific topic over time and therefore want to scrape all pages of a number of online newspapers on a daily basis. Both for the sake of documentation as well as for the sake of not unnecessarily torturing the server. We would thus have to keep track of when the crawler visited what page. A simple way of doing this is to add a column with a time stamp to the crawling history. In R we can do this by calling the function Sys.time() without any function argument which simply returns the date and time of your system (computer), e.g., [1] "2017-09-02 12:44:40 CEST". We can thus extend the code example discussed in the last chapter by adding this to the information stored in the log-file. For this, we first extend the initial log-file (initiated before the loop),
# initiate empty list to keep track of crawler history (visited pages)
crawl_hist <- matrix(ncol = 3, nrow = 0)
colnames(crawl_hist) <- c("visited_URL", "time_visited", "found_URLs")and then extend the DATA PART section within the loop.
# DATA PART -----
# create log entry
log_df <- data.frame(visited_URL = current_URL,
time_visited = Sys.time(),
URLs_found = URLs)
# add to crawler history
crawl_hist <- rbind(crawl_hist, as.matrix(log_df))9.1.3 Changes over time
When repeatedly crawling the same website in order to extract data from its pages, we might want to only update our data set in case of changes (in order to avoid redundancies and save memory). One way of doing this is to inspect the HTTP headers of the response for a last-modified entry that tells us the date the page was changed the last time according to the host. However, this information is not always very reliable. This can be implemented by inspecting the respective entry of the HTTP response headers with httr’s headers() and parse_http_date() right after parsing the response in the first part of the crawler. For simplicity we assume in the following code example that we set the variable last_crawled to the date when we’ve run the crawler for the last time.
# DEQUEUEING AND FETCHING OF WEBPAGE -----
# dequeue URL from frontier
current_URL <- frontier[1]
# fetch page via HTTP
resp <- GET(current_URL)
# parse HTTP headers, check last modified
headers <- headers(resp)
last_modified <- headers$`last-modified`
# parse the date and compare it with the last time the page was visited
last_modified <- parse_http_date(last_modified)
if (last_crawled <= last_modified) {
# parse HTML
html_doc <- read_html(resp)
...
} else {
...
}9.2 Robustness
A key aspect to prevent a crawler from breaking down is to ensure that the canonicalization of URLs is considering all eventualities. In order to make sure that the crawler is not breaking in case of an unforeseen error in the URL construction, we can additionally use the try()-function as a safeguard for each iteration. Regarding HTTP errors, the usual safeguards can be implemented in the first part of the crawler (checking the status of the HTTP response). Unlike in a simple web scraper, it might be more important to keep track of errors when implementing a crawler. A simple way of doing this is to add the error message (returned from try() or GET()) to the crawling history (or a separate log file) and then moving on with the next URL in the frontier. Thus two parts of the crawler script are extended to implement this. In the first part, we add the try(), and in the DATA PART we add the potential error message to the log-file.
# DEQUEUEING AND FETCHING OF WEBPAGE -----
# dequeue URL from frontier
current_URL <- frontier[1]
# fetch page via HTTP
resp <- try(GET(current_URL))
if (class(resp)[1]!="try-error") {
# parse HTML
html_doc <- read_html(resp)
...
} else {
# DATA PART -----
# create log entry
log_df <- data.frame(visited_URL = current_URL, error = resp, URLs_found = NA)
# add to crawler history
crawl_hist <- rbind(crawl_hist, as.matrix(log_df))
...
}9.3 Politeness
Crawlers tend to visit many websites and often visit the same webpages repeatedly. In a sense, they are also more detached from the usual human user than simple scrapers, because it is not strictly defined (and usually cannot be exactly known by the crawler developer) which pages a crawler will eventually visit. There are two broad concerns regarding this: (1) how much bandwidth/resources does a crawler use up when visiting many pages of the same website (in parallel or consecutively). This concern is basically addressed in the time management section above. And, related to this, (2) what pages are actually visited (and scraped) by the crawler. Some webmasters might not want crawlers on their website or on some of its webpages. In such cases, it is common practice that the server provides a file called robots.txt that informs crawlers (in a standardized format) about what is allowed and what is not allowed on this website.26 In the most extreme case, robots.txt might state that crawlers/‘robots’ are not allowed to visit any of the pages of a website. In other cases it might simply specify which pages of a website a crawler is allowed to visit and which it is not allowed to visit. In practice this means that a crawler should be able to automatically parse robots.txt and act according to its instructions. Usually, robots.txt is in the root directory of a website. For example, the robots.txt file of www.google.com is located in www.google.com/robots.txt. In the simplest (and most restrictive case), the content of robots.txt would look like this:
User-agent: *
Disallow: /The first line, User-agent: *, states that the following rules must be obeyed by all robots (*). Alternatively, this line could specify that the rules are only directed towards certain robots.27 The second line simply states that the entire root directory /, meaning the entire website is a no-go-area for crawlers. The rules can, of course, be more complex than this. Allowing some crawlers to visit some pages but not others, etc.28
If we want to inspect a robots.txt file via R, the simplest way is to just send a GET()-request with the respective URL and look at the raw text-file. However, there is also a specific package written to work with robots.txt-files in R: robotstxt. The following code chunk illustrates how this package can be applied to fetch and parse robots.txt-files via R.
# install.packages("robotstxt") # if not yet installed
# load package
library(robotstxt)
# fetch and parse Wikipedia's robots.txt
robs <- robotstxt(domain="wikipedia.org")
# look at the notes provided in the robots.txt file
robs$comments[1:5,]## line
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## comment
## 1 # robots.txt for http://www.wikipedia.org/ and friends
## 2 #
## 3 # Please note: There are a lot of pages on this site, and there are
## 4 # some misbehaved spiders out there that go _way_ too fast. If you're
## 5 # irresponsible, your access to the site may be blocked.# have a look at the rules
robs$permissions[1:5,]## field useragent value
## 1 Disallow MJ12bot /
## 2 Disallow Mediapartners-Google* /
## 3 Disallow IsraBot
## 4 Disallow Orthogaffe
## 5 Disallow UbiCrawler /Note how the information in the robots.txt-file can be accessed after parsing it with robotstxt(). One could now implement a set of rules based on the information in robs$permissions. However, the package provides also additional functions that make the implementation of such steps even simpler. For example, we can directly check whether access to a certain page, certain pages is allowed:
# check if it is allowed in general (*)
paths_allowed(paths = "/", domain="wikipedia.org")##
wikipedia.org## [1] TRUE# check if it is allowed for a certain crawler
paths_allowed(paths = "/", domain="wikipedia.org", bot = "Orthogaffe")##
wikipedia.org## [1] TRUE9.4 Spider traps
Similar to simple scraping tasks, crawler implementation can get much more tricky if we have to deal with webpages that make use of new web technologies such as AJAX/JavaScript. One substantial problem that can arise in such dynamic websites is called the ‘spider trap’, which is usually caused by the dynamic construction of webpages and URLs. Following the example in Liu (2011, 313), a spider trap in a web shop such as Amazon could emerge in the following way:
1. The crawler dequeues a URL with the path /x (www.example-webshop.com/x), fetches that page, and adds the extracted links to the frontier.
2. One of the added URLs is a dynamically constructed link to product y, thus the path is /x/y. The crawler follows that link and again adds the newly found URLs to the frontier.
3. One of the added URLs is again a dynamically constructed link, this time back to page x, thus with the path x/y/x. The crawler does not recognize that it has visited this page yet, because the URL to page x was previously www.example-webshop.com/x, whereas this time it is www.example-webshop.com/x/y/x (due to the dynamic generation of the URLs). Thus the crawler would again visit x and then again visit y, and it would just go on and on infinitely, being trapped in the circularity of the dynamically generated URLs pointing to each other’s pages.
9.5 Building crawlers with Rcrawler
In the previous chapter we have implemented a very simple breadth-first crawler with the aim of constructing a link network from Wikipedia pages. The tools used for the implementation where the basic R packages used for other web-mining tasks throughout the course: httr, rvest, a while-loop, etc. While our traditional toolbox basically contains all functionalities to build simple crawlers, some parts of such a program can be more easily implemented with the help of the new Rcrawler package, specifically developed to facilitate the writing of web crawlers in R. This package is particularly helpful to implement more sophisticated crawlers that can also be run in parallel, meaning it can simultaneously send requests to a server or several servers. Figure 9.1 illustrates the basic architecture of the package which gives an overview of its functionalities and how it works.
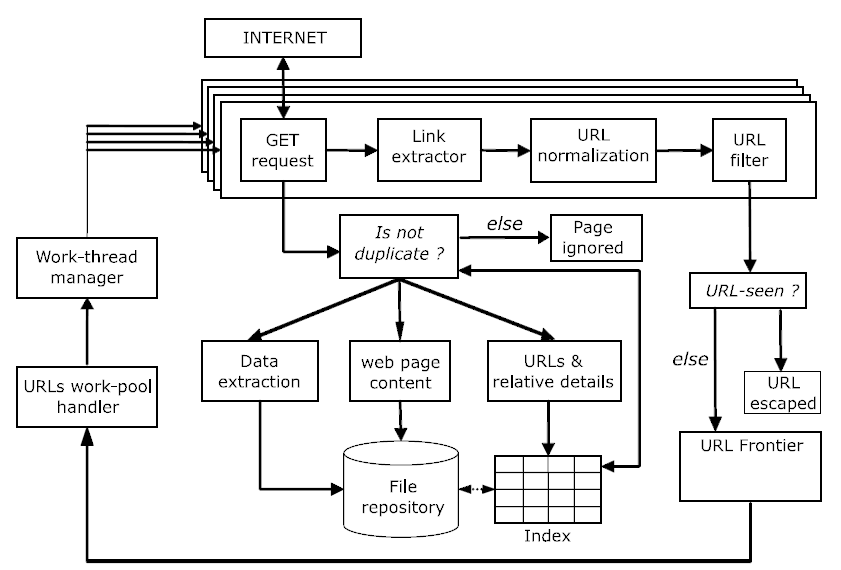
Figure 9.1: Architecture and main components of Rcrawler. Source: Khalil and Fakir (2017).
Note how the core aspects in the outer layer of the architecture reflect the basic crawling algorithm scheme seen in the previous chapter. URLs are dequeued from the frontier, a GET request is issued, URLs are extracted from the HTML document returned by the server, URLs are standardized, URLs are filtered , URLs that haven’t been visited yet are added to the Frontier, etc.29 The inner layer is dealing with what is actually done with the content of the crawled webpages. After making sure that the content of the current page has not already been parsed, the framework of Rcrawler offers several options of how to proceed with the actual content of the page: Extract a specific part of the page and store it, store the entire page, store URLs and metadata.30
An important distinction between the simple crawler schema introduced in the previous chapter is the ‘URLs work-pool handler’ and the ‘work-thread manager’. These are the parts of Rcrawler that deal with the parallelization of the crawling task. That is, in simple terms, they prepare and distribute different URLs to different processors/cores of processors (‘nodes’) on a computer. Each of these nodes is then processing the main crawling tasks for the respective URL in parallel. Thus in each iteration, not only one URL is dequeued from the frontier, but several URLs at a time (‘a pool of URLs’). Figure 9.2 illustrates how this is implemented in more detail.
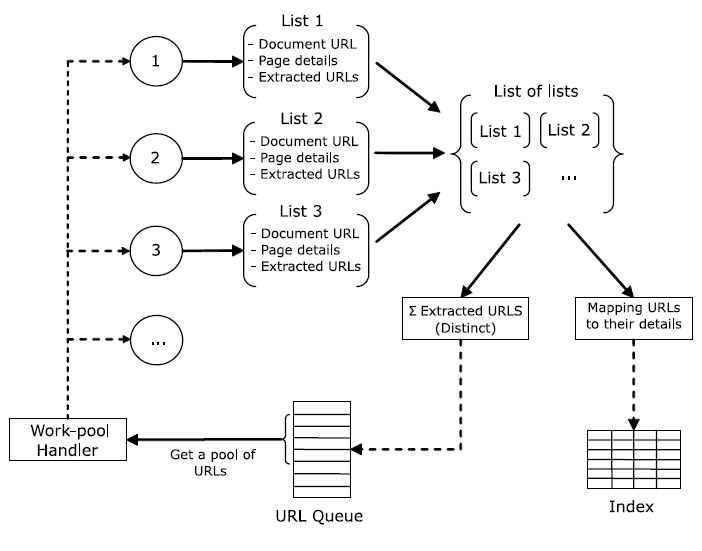
Figure 9.2: Design of our multi-threading implementation in the R environment. Source: Khalil and Fakir (2017).
Apart from providing a framework to easily parallelize crawlers, Rcrawler also provides several functions that can be helpful to implement various aspects of a crawler. In the simple breadth-first crawler implemented during the last chapter, for example, the canonicalization of URLs is done with Rcrawler’s LinkNormalization()-function.
# LINK EXTRACTION -----
# extract all URLs
links_nodes <- html_nodes(html_doc, xpath = ".//a")
URLs <- html_attr(links_nodes, name = "href")
# clean URLs
# remove anchors
URLs <- URLs[!grepl("#", URLs, fixed = TRUE)]
# remove NAs
URLs <- na.omit(URLs)
# canonicalize URLs, only keep unique entries
URLs <- unique(LinkNormalization(links = URLs, current = current_URL))
# add to tail of frontier (first-in-first-out -> breadth first)
frontier <- c(frontier, URLs)Finally, Rcrawler provides several high-level functions that directly implement a crawler. In the following code example we implement a crawler similar to the manual implementation of our Wikipedia crawler with the help of such functions.
#######################################################
# Introduction to Web Mining 2017
# 9: Crawlers, Spiders, Scrapers Part II
#
# Crawler implementation:
# A simple breadth-first web crawler collecting the
# link structure up to n visited pages based on the
# Rcrawler package
#
# U.Matter, November 2017
#######################################################
# PREAMBLE -----
# load packages
library(Rcrawler)
# initiate frontier vector with initial URL as seed
# (Rcrawler only accepts one, this is a disadvantage)
frontier <- "https://en.wikipedia.org/wiki/George_Stigler"
# initiate a crawl-repository track of crawler history (visited pages, etc.)
crawl_hist <- "./wiki_crawler"
# initiate control variables
# set limit of pages to be visited
max_depth <- 0
# START CRAWLING ITERATION ----
# Networkdata= TRUE makes the crawler store information on the link structure
# which pages link to which other pages
Rcrawler(frontier, MaxDepth = max_depth, DIR = crawl_hist, NetworkData = TRUE)
# ANALYZE LINK STRUCTURE ----
# The extracted link structure can then directly be analyzed:
# load igraph package (to plot networks)
library(visNetwork)
# convert extracted link structure to igraph-object
edges <- NetwEdges[1:50,]
names(edges) <- tolower(names(edges))
nodes <- data.frame(id=unique(c(edges$from, edges$to)))
# plot the network
visNetwork(nodes,edges)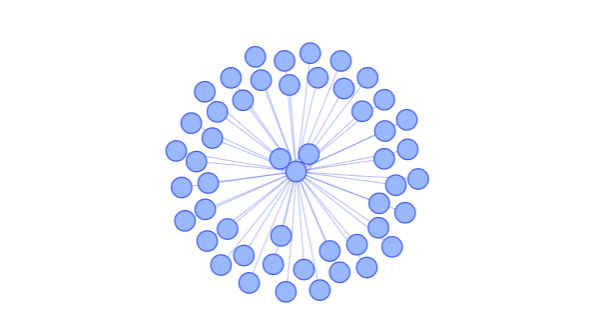
References
We will look at the implications of
robots.txtin more detail in the next chapter.↩︎For example,
robots.txtcould specify that Google’s crawlers are not welcome, in case one does not want to be indexed by Google’s search engine.↩︎See, for example, the rules in
www.google.com/robots.txt.↩︎Both the URL filtering step and the adding to the frontier are decisive with regard to what type of algorithm is implemented: breadth-first or priority queue.↩︎
Note how the simple breadth-first crawler implemented during the last chapter only stored URLs and how they link to each other, i.e., which page links to which other pages. However, at the step in the R script where we’ve implemented the extraction and storage of URLs could be easily extended with the other options that the
Rcrawlerpackage offers. Thus, the basic architecture ofRcrawleris also reflected in our simple blueprint for a web crawler in form of an R script based on the usual toolshttrandrvest.↩︎